Menu

Everything you need to know about withdrawing, staking, and voting with your $AZTEC tokens
The $AZTEC token sale was conducted entirely onchain to maximize transparency and fair distribution. Next steps for holders are as follows:
The $AZTEC token sale has come to a close– the sale was conducted entirely onchain, and the power is now in your hands. Over 16.7k people participated, with 19,476 ETH raised. A huge thank you to our community and everyone who participated– you all really showed up for privacy. 50% of the capital committed has come from the community of users, testnet operators and creators!
Now that you have your tokens, what’s next? This guide walks you through the next steps leading up to TGE, showing you how to withdraw, stake, and vote with your tokens.
The $AZTEC sale was conducted onchain to ensure that you have control over your own tokens from day 1 (even before tokens become transferable at TGE).
The team has no control over your tokens. You will be self-custodying them in a smart contract known as the Token Vault on the Ethereum mainnet ahead of TGE.
Your Token Vault contract will:
To create and withdraw your tokens to your Token Vault, simply go to the sale website and click on ‘Create Token Vault.’ Any unused ETH from your bids will be returned to your wallet in the process of creating your Token Vault.
If you have 200,000+ tokens, you are eligible to start staking and earning block rewards today.
You can stake by connecting your Token Vault to the staking dashboard, just select a provider to delegate your stake. Alternatively, you can run your own sequencer node.
If your Token Vault holds 200,000+ tokens, you must stake in order to withdraw your tokens after TGE. If your Token Vault holds less than 200,000 tokens, you can withdraw without any additional steps at TGE
Fractional staking for anyone with less than 200,000 tokens is not currently supported, but multiple external projects are already working to offer this in the future.
TGE is triggered by an onchain governance vote, which can happen as early as February 11th, 2026.
At TGE, 100% of tokens from the token sale will be transferable. Only token sale participants and genesis sequencers can participate in the TGE vote, and only tokens purchased in the sale will become transferrable.
Community members discuss potential votes on the governance forum. If the community agrees, sequencers signal to start a vote with their block proposals. Once enough sequencers agree, the vote goes onchain for eligible token holders.
Voting lasts 7 days, requires participation of at least 100,000,000 $AZTEC tokens, and passes if 2/3 vote yes.
Following a successful yes vote, anyone can execute the proposal after a 7-day execution delay, triggering TGE.
At TGE, the following tokens will be 100% unlocked and available for trading:
Join us Thursday, December 11th at 3 pm UTC for the next Discord Town Hall–AMA style on next steps for token holders. Follow Aztec on X to stay up to date on the latest developments.
We invented the math. We wrote the language. Proved the concept and now, we’re opening registration and bidding for the $AZTEC token today, starting at 3 pm CET.
The community-first distribution offers a starting floor price based on a $350 million fully diluted valuation (FDV), representing an approximate 75% discount to the implied network valuation (based on the latest valuation from Aztec Labs’ equity financings). The auction also features per-user participation caps to give community members genuine, bid-clearing opportunities to participate daily through the entirety of the auction.
The token auction portal is live at: sale.aztec.network
We’ve taken the community access that made the 2017 ICO era great and made it even better.
For the past several months, we've worked closely with Uniswap Labs as core contributors on the CCA protocol, a set of smart contracts that challenge traditional token distribution mechanisms to prioritize fair access, permissionless, on-chain access to community members and the general public pre-launch. This means that on day 1 of the unlock, 100% of the community's $AZTEC tokens will be unlocked.
This model is values-aligned with our Core team and addresses the current challenges in token distribution, where retail participants often face unfair disadvantages against whales and institutions that hold large amounts of money.
Early contributors and long-standing community members, including genesis sequencers, OG Aztec Connect users, network operators, and community members, can start bidding today, ahead of the public auction, giving those who are whitelisted a head start and early advantage for competitive pricing. Community members can participate by visiting the token sale site to verify eligibility and mint a soul-bound NFT that confirms participation rights.
To read more about Aztec’s fair-access token sale, visit the economic and technical whitepapers and the token regulatory report.
Discount Price Disclaimer: Any reference to a prior valuation or percentage discount is provided solely to inform potential purchasers of how the initial floor price for the token sale was calculated. Equity financing valuations were determined under specific circumstances that are not comparable to this offering. They do not represent, and should not be relied upon as, the current or future market value of the tokens, nor as an indication of potential returns. The price of tokens may fluctuate substantially, the token may lose its value in part or in full, and purchasers should make independent assessments without reliance on past valuations. No representation or warranty is made that any purchaser will achieve profits or recover the purchase price.
Information for Persons in the UK: This communication is directed only at persons outside the UK. Persons in the UK are not permitted to participate in the token sale and must not act upon this communication.
MiCA Disclaimer: Any crypto-asset marketing communications made from this account have not been reviewed or approved by any competent authority in any Member State of the European Union. Aztec Foundation as the offeror of the crypto-asset is solely responsible for the content of such crypto-asset marketing communications. The Aztec MiCA white paper has been published and is available here. The Aztec Foundation can be contacted at hello@aztec.foundation or +41 41 710 16 70. For more information about the Aztec Foundation, visit https://aztec.foundation.
Every time you swap tokens on Uniswap, deposit into a yield vault, or vote in a DAO, you're broadcasting your moves to the world. Anyone can see what you own, where you trade, how much you invest, and when you move your money.
Tracking and analysis tools like Chainalysis and TRM are already extremely advanced, and will only grow stronger with advances in AI in the coming years. The implications of this are that the ‘pseudo-anonymous’ wallets on Ethereum are quickly becoming linked to real-world identities. This is concerning for protecting your personal privacy, but it’s also a major blocker in bringing institutions on-chain with full compliance for their users.
Until now, your only option was to abandon your favorite apps and move to specialized privacy-focused apps or chains with varying degrees of privacy. You'd lose access to the DeFi ecosystem as you know it now, the liquidity you depend on, and the community you're part of.
What if you could keep using Uniswap, Aave, Yearn, and every other app you love, but with your identity staying private? No switching chains. Just an incognito mode for your existing on-chain life?
If you’ve been following Aztec for a while, you would be right to think about Aztec Connect here, which was hugely popular with $17M TVL and over 100,000 active wallets, but was sunset in 2024 to focus on bringing a general-purpose privacy network to life.
Read on to learn how you’ll be able to import privacy to any L2, using one of the many privacy-focused bridges that are already built.
Aztec is a fully decentralized, privacy-preserving L2 on Ethereum. You can think of Aztec as a private world computer with full end-to-end programmable privacy. A private world computer extends Ethereum to add optional privacy at every level, from identity and transactions to the smart contracts themselves.
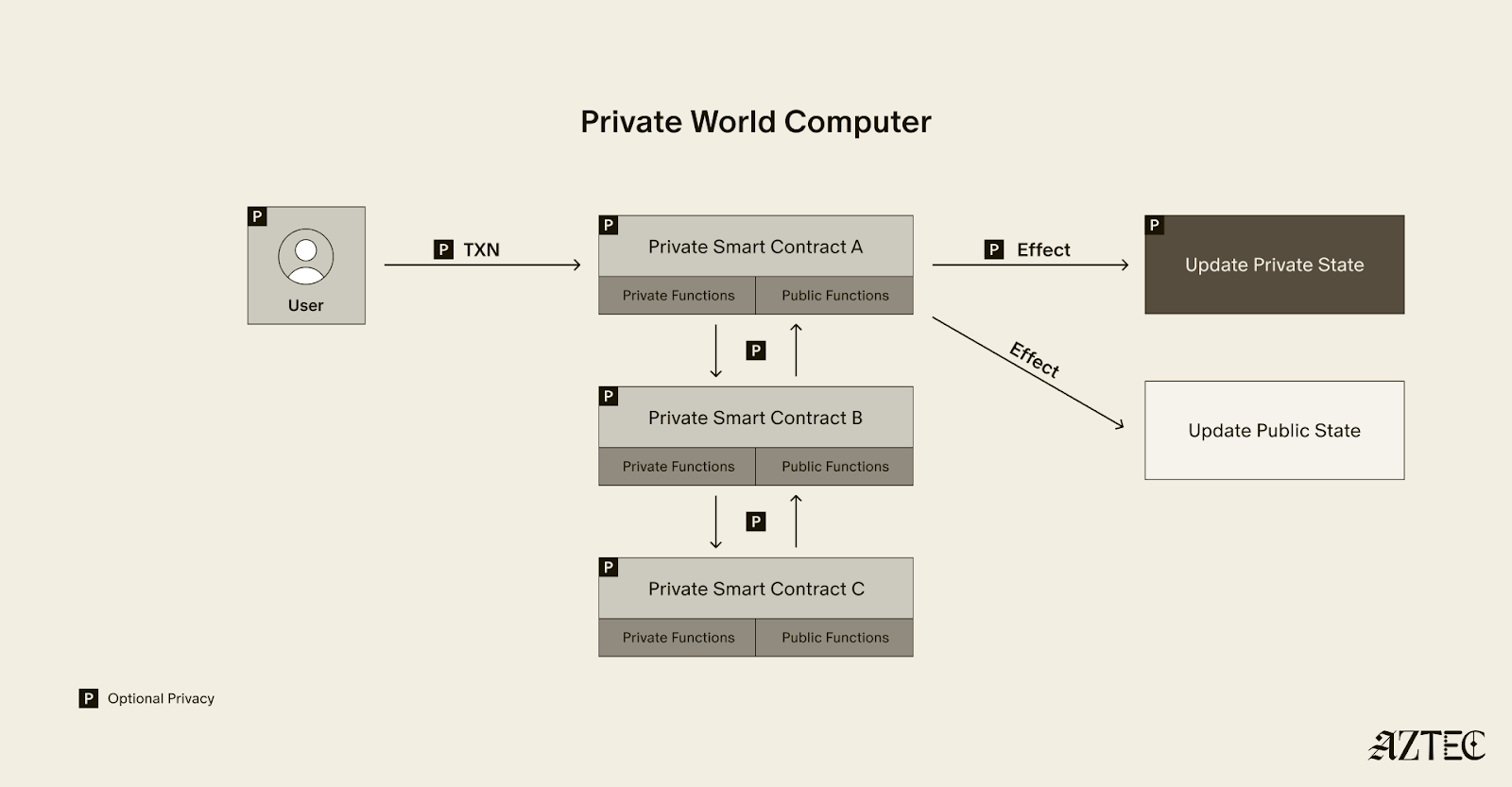
On Aztec, every wallet is a smart contract that gives users complete control over which aspects they want to make public or keep private.
Aztec is currently in Testnet, but will have multiple privacy-preserving bridges live for its mainnet launch, unlocking a myriad of privacy preserving features.
Now, several bridges, including Wormhole, TRAIN, and Substance, are connecting Aztec to other chains, adding a privacy layer to the L2s you already use. Think of it as a secure tunnel between you and any DeFi app on Ethereum, Arbitrum, Base, Optimism, or other major chains.
Here's what changes: You can now use any DeFi protocol without revealing your identity. Furthermore, you can also unlock brand new features that take advantage of Aztec’s private smart contracts, like private DAO voting or private compliance checks.
Here's what you can do:
The apps stay where they are. Your liquidity stays where it is. Your community stays where it is. You just get a privacy upgrade.
Let's follow Alice through a real example.
Alice wants to invest $1,000 USDC into a yield vault on Arbitrum without revealing her identity.
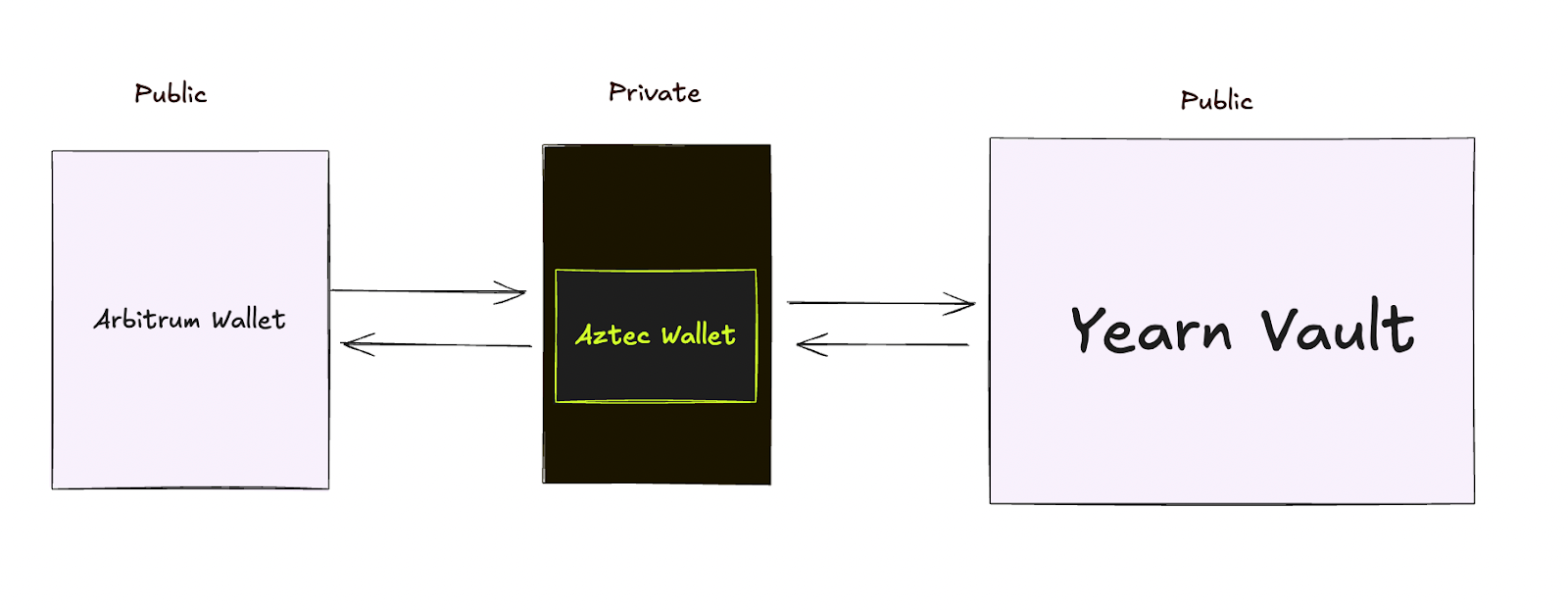
Alice moves her funds into Aztec's privacy layer. This could be done in one click directly in the app that she’s already using if the app has integrated one of the bridges. Think of this like dropping a sealed envelope into a secure mailbox. The funds enter a private space where transactions can't be tracked back to her wallet.
Aztec routes Alice's funds to the Yearn vault on Arbitrum. The vault sees a deposit and issues yield-earning tokens. But there's no way to trace those tokens back to Alice's original wallet. Others can see someone made a deposit, but they have no idea who.
The yield tokens arrive in Alice's private Aztec wallet. She can hold them, trade them privately, or eventually withdraw them, without anyone connecting the dots.
Alice is earning yield on Arbitrum using the exact same vault as everyone else. But while other users broadcast their entire investment strategy, Alice's moves remain private.
The difference looks like this:
Without privacy: "Wallet 0x742d...89ab deposited $5,000 into Yearn vault at 2:47 PM"
With Aztec privacy: "Someone deposited funds into Yearn vault" (but who? from where? how much? unknowable).
In the future, we expect apps to directly integrate Aztec, making this experience seamless for you as a user.
While Aztec is still in Testnet, multiple teams are already building bridges right now in preparation for the mainnet launch.
Projects like Substance Labs, Train, and Wormhole are creating connections between Aztec and major chains like Optimism, Unichain, Solana, and Aptos. This means you'll soon have private access to DeFi across nearly every major ecosystem.
Aztec has also launched a dedicated cross-chain catalyst program to support developers with grants to build additional bridges and apps.
L2s have sometimes received criticism for fragmenting liquidity across chains. Aztec is taking a different approach. Instead, Aztec is bringing privacy to the liquidity that already exists. Your funds stay on Arbitrum, Optimism, Base, wherever the deepest pools and best apps already live. Aztec doesn't compete for liquidity, it adds privacy to existing liquidity.
You can access Uniswap's billions in trading volume. You can tap into Aave's massive lending pools. You can deposit into Yearn's established vaults, all without moving liquidity away from where it's most useful.
We’re rolling out a new approach to how we think about L2s on Ethereum. Rather than forcing users to choose between privacy and access to the best DeFi applications, we’re making privacy a feature you can add to any protocol you're already using. As more bridges go live and applications integrate Aztec directly, using DeFi privately will become as simple as clicking a button—no technical knowledge required, no compromise on the apps and liquidity you depend on.
While Aztec is currently in testnet, the infrastructure is rapidly taking shape. With multiple bridge providers building connections to major chains and a dedicated catalyst program supporting developers, the path to mainnet is clear. Soon, you'll be able to protect your privacy while still participating fully in the Ethereum ecosystem.
If you’re a developer and want a full technical breakdown, check out this post. To stay up to date with the latest updates for network operators, join the Aztec Discord and follow Aztec on X.
OTC trading is fundamental to how crypto markets function. It enables better price negotiations than what you'll find on public order books and facilitates trading of illiquid assets that barely exist on exchanges. Without OTC markets, institutional crypto trading would be nearly impossible. But here's the massive problem: every single OTC transaction leaves a permanent, public trace.
Let's say you're a fund manager who needs to sell 1,000 BTC for USDC on Base. In a traditional OTC trade, your Bitcoin leaves your wallet and becomes visible to everyone on Bitcoin's blockchain. Through cross-chain settlement, USDC then arrives in your Base wallet, which is also visible to everyone on Base's blockchain.
At this point, block explorers and analytics firms can connect these transactions through pattern analysis. As a result, your trading patterns, position sizes, and timing become public data, exposing your entire strategy.
This isn't just about privacy; transparent OTC creates serious operational and strategic risks. These same concerns have moved a significant portion of traditional markets to private off-exchange trades.
In TradFi, institutions don't execute large trades on public order books for many reasons. In fact, ~13% of all stocks in the US are now traded in dark pools, and more than 50% of trades are now off-exchange.
They use private networks, dark pools, and OTC desks specifically because:
While OTC trading is already a major part of the crypto industry, without privacy, true institutional participation will never be practical.
Now, Aztec is making this possible.
We built an open-source private OTC trading system using Aztec Network's programmable privacy features. Because Aztec allows users to have private, programmable, and composable private state, users aren’t limited to only owning and transferring digital assets privately, but also programming and composing them via smart contracts.
If you’re new to Aztec, you can think of the network as a private world computer, with full end-to-end programmable privacy. A private world computer extends Ethereum to add optional privacy at every level, from identity and transactions to the smart contracts themselves.
To build a private OTC desk, we leveraged all these tools provided by Aztec to implement a working proof of concept. Our private OTC desk is non-custodial and leverages private smart contracts and client-side proving to allow for complete privacy of the seller and buyer of the OTC.
How It Actually Works
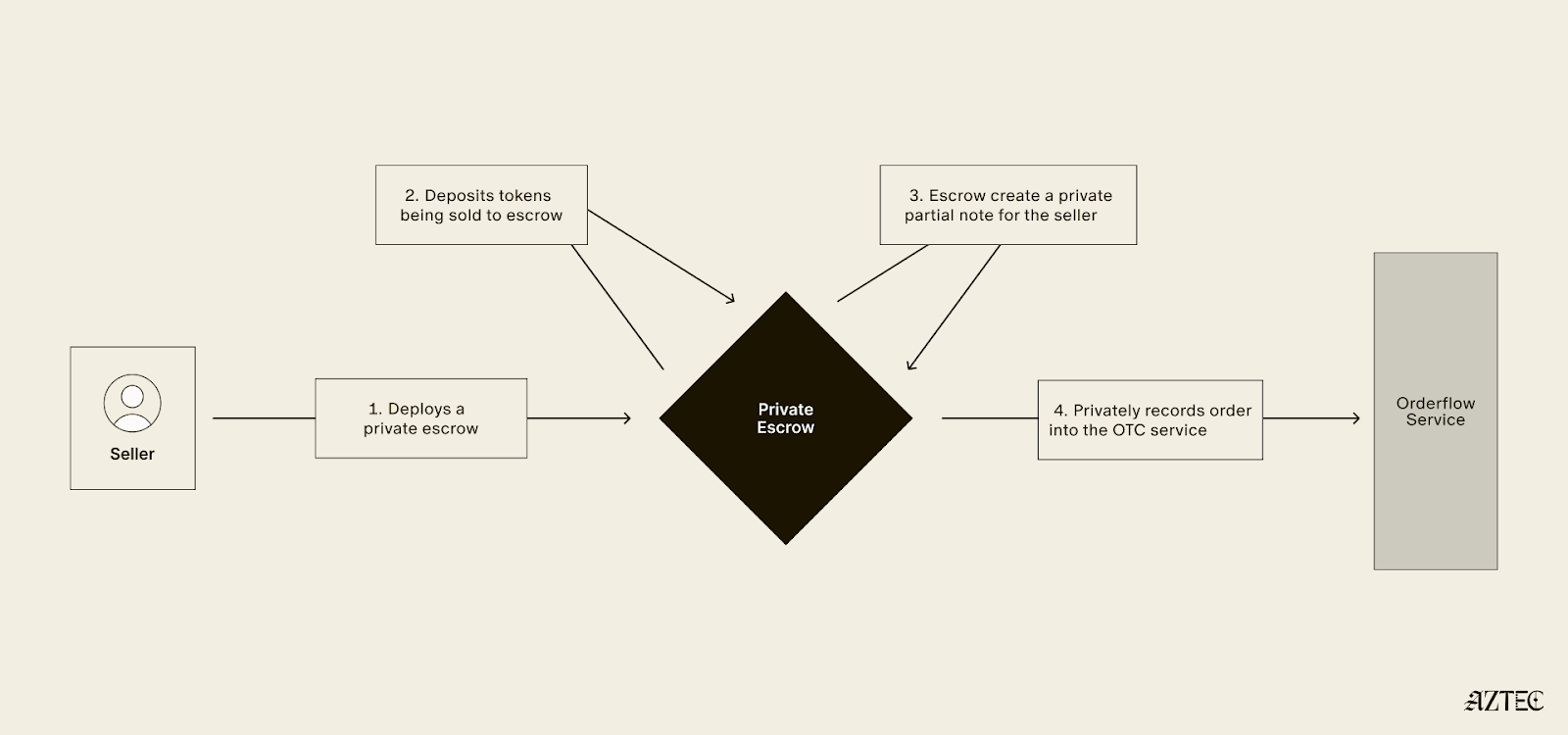
For Sellers:

For Buyers:
The Magic: Partial Notes are the technical breakthrough that make collaborative, asynchronous private transactions possible. Sellers create incomplete payment commitments that buyers can finish without revealing the seller's identity. It's like leaving a blank check that only the right person can cash, but neither party knows who the other is.
Privacy guarantees include:
Private Contract Deployment: Unlike public decentralized exchanges where smart contracts are visible on the blockchain, the escrow contracts in this system are deployed privately, meaning that only the participants involved in the transaction know these contracts exist.
Partial Note Mechanism: This system uses cryptographic primitives that enable incomplete commitments to be finalized or completed by third parties, all while preventing those third parties from revealing or accessing any pre-existing information that was part of the original commitment.
Privacy-Preserving Discovery: The orderflow service maintains knowledge of aggregate trading volumes and overall market activity, but it cannot see the details of individual traders, including their specific trade parameters or personal identities.
Atomic Execution: The smart contract logic is designed to ensure that both sides of a trade occur simultaneously in a single atomic operation, meaning that if any part of the transaction fails, the entire transaction is rolled back and neither party's assets are transferred.
Our prototype for this is open-sourced here, and you can read about the proof of concept directly from the developer here.
We're inviting teams to explore, fork, and commercialize this idea. The infrastructure for private institutional trading needs to exist, and Aztec makes it possible today. Whether you're building a private DEX, upgrading your OTC desk, or exploring new DeFi primitives, this codebase is your starting point.
The traditional finance world conducts trillions in private OTC trades. It's time to bring that scale to crypto, privately.
To stay up to date with the latest updates for network operators, join the Aztec Discord and follow Aztec on X.
Watch this: Alice sends Zcash. Bob receives USDC on Aztec. Nobody, not even the system facilitating it, knows who Alice or Bob are.
And Bob can now do something with that money. Privately.
This is the connection between private money and a private economy where that money can actually be used.
Zcash has already achieved something monumental: truly private money. It’s the store of value that Bitcoin promised (but made transparent). Like, digital gold that actually stays hidden.
But here's the thing about gold - you don't buy coffee with gold bars. You need an economy where that value can flow, work, and grow. Privately.
While other projects are trying to bolt privacy onto existing chains as an afterthought, Zcash is one of the oldest privacy projects in Web3. It's achieved what dozens of projects are still chasing: a truly private store of value.
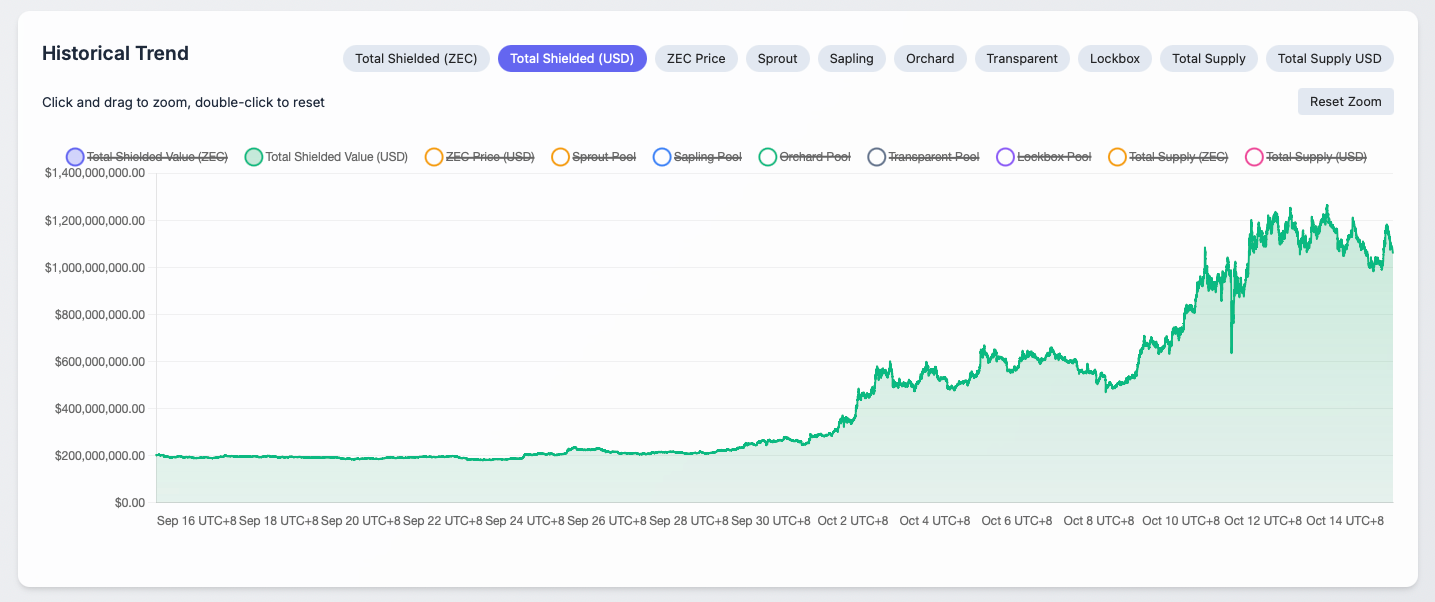
This is critical infrastructure for freedom. The ability to store value privately is a fundamental right, a hedge against surveillance, and a given when using cash. We need a system that provides the same level of privacy guarantees as cash. Right now, there's over $1.1 billion sitting in Zcash's shielded pool, private wealth that's perfectly secure but essentially frozen.
Why frozen? Because the moment that shielded $ZEC tries to do anything beyond basic transfers: earn yield, get swapped for stablecoins, enter a liquidity pool, it must expose itself. The privacy in this format is destroyed.
This isn't Zcash's failure. They built exactly what they set out to build: the world's best private store of value. The failure is that the rest of crypto hasn't built where that value can actually work.
The Privacy Landscape Has an Imbalance
What happens when you want to do more than just send money? What happens when you want privacy after you transfer your money?

Private Digital Money (i.e., “Transfer Privacy,” largely solved by Zcash):
Private World Computer (i.e., After-the-Transfer Privacy):
Everyone else is competing to build better ways to hide money. Zcash has already built the private store of value, and Aztec has built the only way to use hidden money.
Here's the trillion-dollar question: What good is private money if you can't use it?
Right now, Zcash's shielded pool contains billions in value. This is money in high-security vaults. But unlike gold in vaults that can be collateralized, borrowed against, or deployed, this private value just sits there.
Every $ZEC holder faces two impossible choices:
Our demo breaks this false sense of choice. For the first time, shielded value can move to a place where it remains private AND becomes useful.
Here's how you can identify whether you’re dealing with a private world computer, or just private digital money:
Without a private world computer (every other privacy solution):
With a private world computer (only Aztec):
This is basic financial common sense. Your money should grow. It should work. It should be useful.
The technical reality is that this requires private smart contracts. Aztec is building the only way to interact privately with smart contracts. These smart contracts themselves can remain completely hidden. Your private money can finally do what money is supposed to do: work for you.
Our demo proves these two worlds can connect:
We built the bridge between storing privately and doing privately.
The technical innovation - "partial notes" - are like temporary lockboxes that self-destruct after one use. Money can be put privately into these lockboxes, and a key can be privately handed to someone to unlock it. No one knows who put the money in, where the key came from, or who uses the key. You can read more about how they work here. But what matters isn't the mechanism.
What matters is that Alice's Zcash can become Bob's working capital on Aztec without anyone knowing about either of them.
As a result, Bob receives USDC that he can:
You can't bolt privacy onto existing systems. You can't take Ethereum and make it private. You can't take a transparent smart contract platform and add privacy as a feature.
Aztec had to be built from the ground up as a private world computer because after-the-transfer privacy requires rethinking everything:
This is why there's only one name building fully private smart contracts. From the beginning, Aztec has been inspired by the work Zcash has done to create a private store of value. That’s what led to the vision for a private world computer.
Everyone else is iterating on the same transfer privacy problem. Aztec solves a fundamentally different problem.
Once you see it, you can't unsee it: Privacy without utility is only the first step.
Every privacy project will eventually need what Aztec built. Because their users will eventually ask: "Okay, my money is private... now what?"
This demo that connects Zcash to Aztec is the first connection between the old world (private transfers) and the new world (private everything else).
For Zcash Holders: Your shielded $ZEC can finally do something without being exposed.
For Developers: Stop trying to build better mattresses to hide money under. Start building useful applications on the only platform that keeps them private.
For the Industry: The privacy wars are over. There's transfer privacy (solved by Zcash) and after-the-transfer privacy (just Aztec).
This demo is live. The code is open source. The bridge between private money and useful private money exists.
But this is just the beginning. Every privacy project needs this bridge. Every private payment network needs somewhere for those payments to actually be used.
We're not competing with transfer privacy. We're continuing it.
Your private money yearns for the private economy.
Welcome to after-the-transfer privacy. Welcome to Aztec.
Privacy has emerged as a major driver for the crypto industry in 2025. We’ve seen the explosion of Zcash, the Ethereum Foundation’s refocusing of PSE, and the launch of Aztec’s testnet with over 24,000 validators powering the network. Many apps have also emerged to bring private transactions to Ethereum and Solana in various ways, and exciting technologies like ZKPassport that privately bring identity on-chain using Noir have become some of the most talked about developments for ushering in the next big movements to the space.
Underpinning all of these developments is the emerging consensus that without privacy, blockchains will struggle to gain real-world adoption.
Without privacy, institutions can’t bring assets on-chain in a compliant way or conduct complex swaps and trades without revealing their strategies. Without privacy, DeFi remains dominated and controlled by advanced traders who can see all upcoming transactions and manipulate the market. Without privacy, regular people will not want to move their lives on-chain for the entire world to see every detail about their every move.
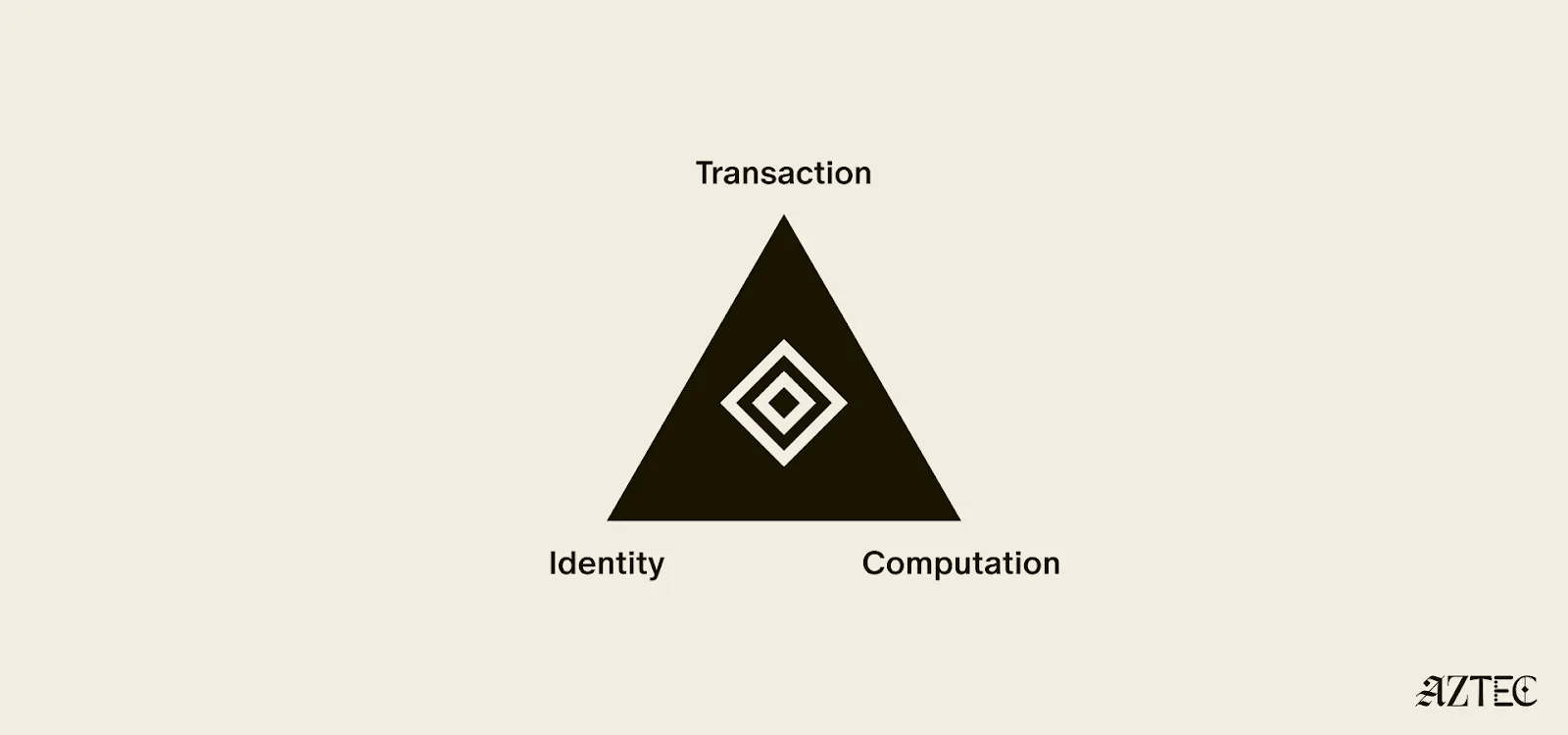
While there's been lots of talk about privacy, few can define it. In this piece we’ll outline the three pillars of privacy and gives you a framework for evaluating the privacy claims of any project.
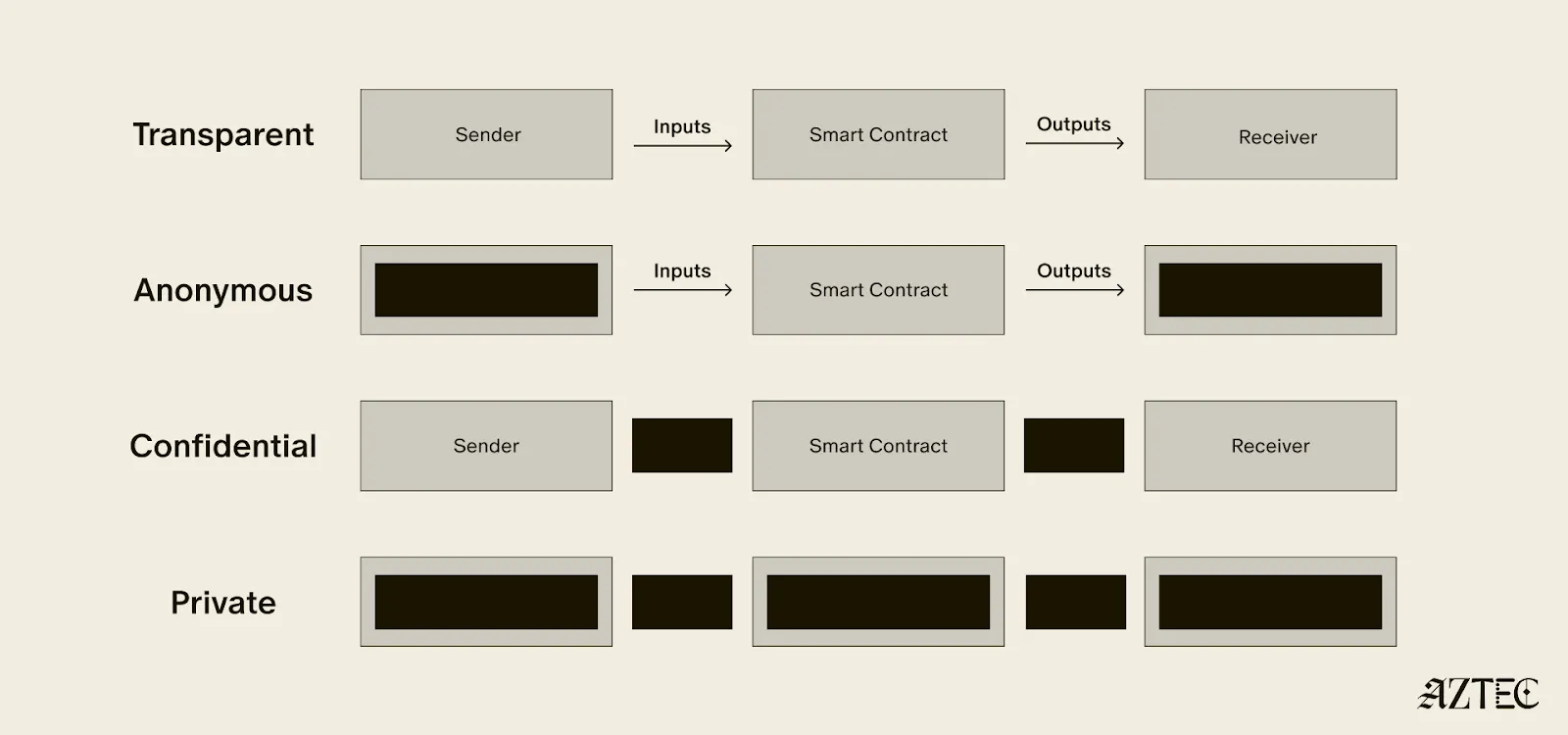
True privacy rests on three essential pillars: transaction privacy, identity privacy, and computational privacy. It is only when we have all three pillars that we see the emergence of a private world computer.
Transaction privacy means that both inputs and outputs are not viewable by anyone other than the intended participants. Inputs include any asset, value, message, or function calldata that is being sent. Outputs include any state changes or transaction effects, or any transaction metadata caused by the transaction. Transaction privacy is often primarily achieved using a UTXO model (like Zcash or Aztec’s private state tree). If a project has only the option for this pillar, it can be said to be confidential, but not private.
Identity privacy means that the identities of those involved are not viewable by anyone other than the intended participants. This includes addresses or accounts and any information about the identity of the participants, such as tx.origin, msg.sender, or linking one’s private account to public accounts. Identity privacy can be achieved in several ways, including client-side proof generation that keeps all user info on the users’ devices. If a project has only the option for this pillar, it can be said to be anonymous, but not private.
Computation privacy means that any activity that happens is not viewable by anyone other than the intended participants. This includes the contract code itself, function execution, contract address, and full callstack privacy. Additionally, any metadata generated by the transaction is able to be appropriately obfuscated (such as transaction effects, events are appropriately padded, inclusion block number are in appropriate sets). Callstack privacy includes which contracts you call, what functions in those contracts you’ve called, what the results of those functions were, any subsequent functions that will be called after, and what the inputs to the function were. A project must have the option for this pillar to do anything privately other than basic transactions.
Bitcoin ushered in a new paradigm of digital money. As a permissionless, peer-to-peer currency and store of value, it changed the way value could be sent around the world and who could participate. Ethereum expanded this vision to bring us the world computer, a decentralized, general-purpose blockchain with programmable smart contracts.
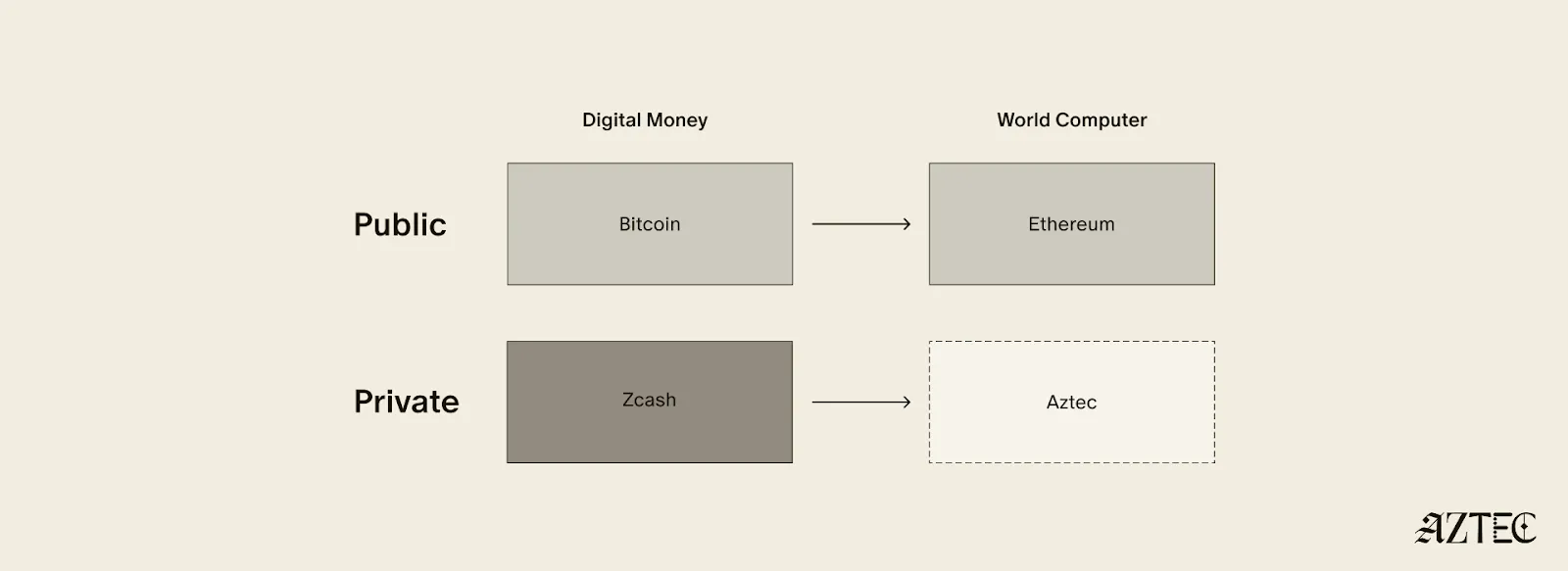
Given the limitations of running a transparent blockchain that exposes all user activity, accounts, and assets, it was clear that adding the option to preserve privacy would unlock many benefits (and more closely resemble real cash). But this was a very challenging problem. Zcash was one of the first to extend Bitcoin’s functionality with optional privacy, unlocking a new privacy-preserving UTXO model for transacting privately. As we’ll see below, many of the current privacy-focused projects are working on similar kinds of private digital money for Ethereum or other chains.
Now, Aztec is bringing us the final missing piece: a private world computer.
A private world computer is fully decentralized, programmable, and permissionless like Ethereum and has optional privacy at every level. In other words, Aztec is extending all the functionality of Ethereum with optional transaction, identity, and computational privacy. This is the only approach that enables fully compliant, decentralized applications to be built that preserve user privacy, a new design space that we see as ushering in the next Renaissance for the space.
Private digital money emerges when you have the first two privacy pillars covered - transactions and identity - but you don’t have the third - computation. Almost all projects today that claim some level of privacy are working on private digital money. This includes everything from privacy pools on Ethereum and L2s to newly emerging payment L1s like Tempo and Arc that are developing various degrees of transaction privacy
When it comes to digital money, privacy exists on a spectrum. If your identity is hidden but your transactions are visible, that's what we call anonymous. If your transactions are hidden but your identity is known, that's confidential. And when both your identity and transactions are protected, that's true privacy. Projects are working on many different approaches to implement this, from PSE to Payy using Noir, the zkDSL built to make it intuitive to build zk applications using familiar Rust-like syntax.
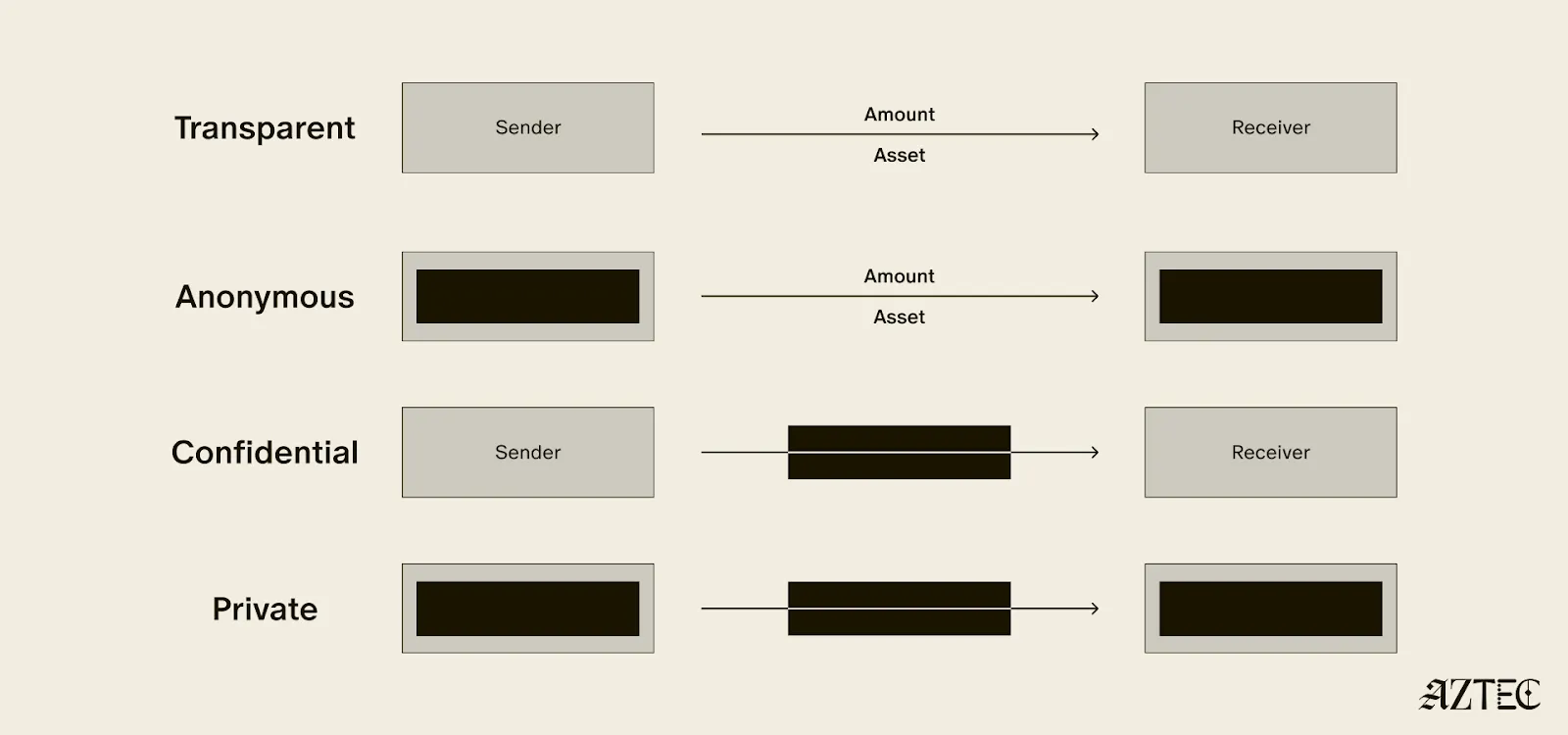
Private digital money is designed to make payments private, but any interaction with more complex smart contracts than a straightforward payment transaction is fully exposed.
What if we also want to build decentralized private apps using smart contracts (usually multiple that talk to each other)? For this, you need all three privacy pillars: transaction, identity, and compute.
If you have these three pillars covered and you have decentralization, you have built a private world computer. Without decentralization, you are vulnerable to censorship, privileged backdoors and inevitable centralized control that can compromise privacy guarantees.
What exactly is a private world computer? A private world computer extends all the functionality of Ethereum with optional privacy at every level, so developers can easily control which aspects they want public or private and users can selectively disclose information. With Aztec, developers can build apps with optional transaction, identity, and compute privacy on a fully decentralized network. Below, we’ll break down the main components of a private world computer.
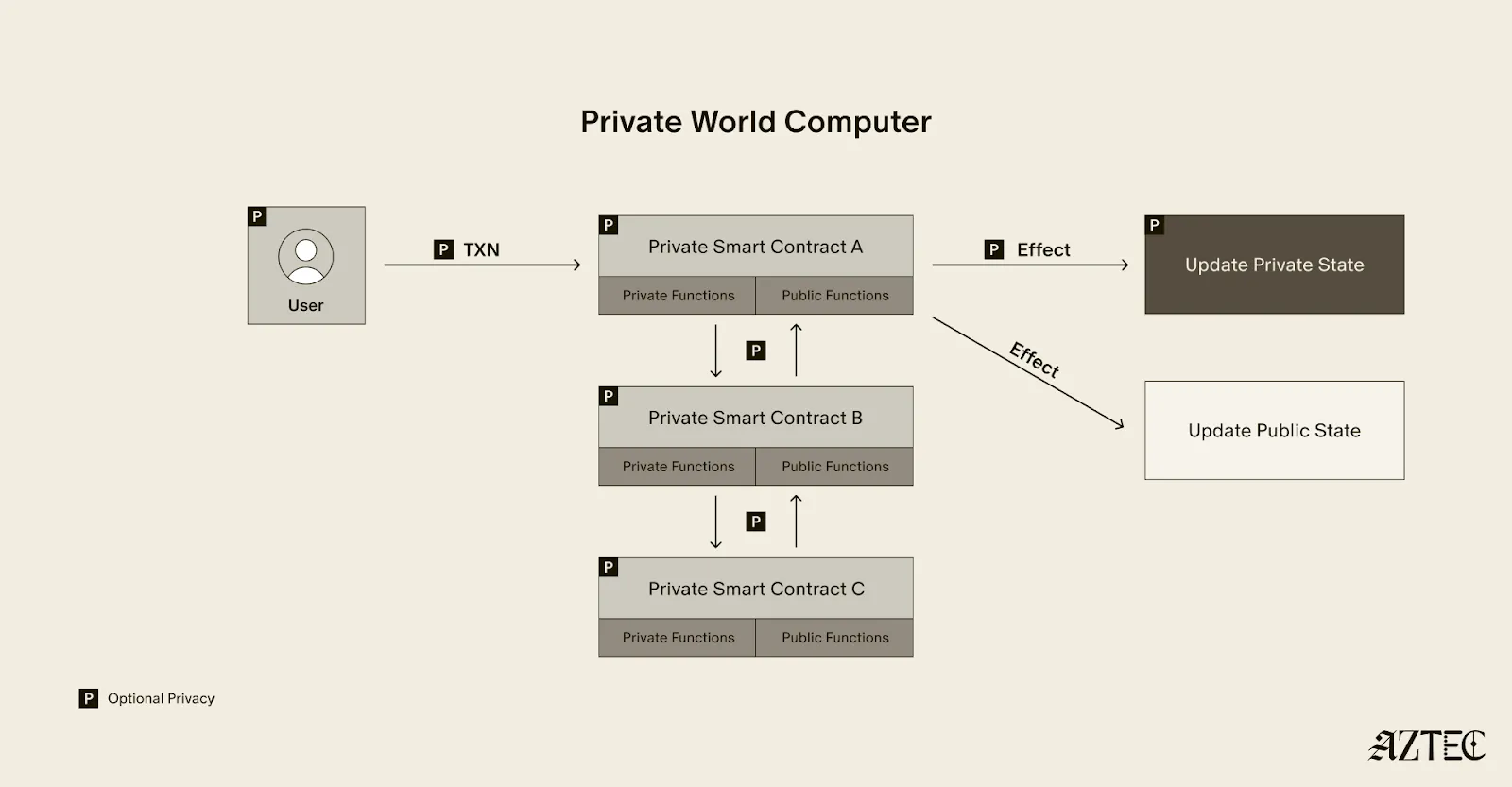
A private world computer is powered by private smart contracts. Private smart contracts have fully optional privacy and also enable seamless public and private function interaction.
Private smart contracts simply extend the functionality of regular smart contracts with added privacy.
As a developer, you can easily designate which functions you want to keep private and which you want to make public. For example, a voting app might allow users to privately cast votes and publicly display the result. Private smart contracts can also interact privately with other smart contracts, without needing to make it public which contracts have interacted.
Transaction: Aztec supports the optionality for fully private inputs, including messages, state, and function calldata. Private state is updated via a private UTXO state tree.
Identity: Using client-side proofs and function execution, Aztec can optionally keep all user info private, including tx.origin and msg.sender for transactions.
Computation: The contract code itself, function execution, and call stack can all be kept private. This includes which contracts you call, what functions in those contracts you’ve called, what the results of those functions were, and what the inputs to the function were.
A decentralized network must be made up of a permissionless network of operators who run the network and decide on upgrades. Aztec is run by a decentralized network of node operators who propose and attest to transactions. Rollup proofs on Aztec are also run by a decentralized prover network that can permissionlessly submit proofs and participate in block rewards. Finally, the Aztec network is governed by the sequencers, who propose, signal, vote, and execute network upgrades.
A private world computer enables the creation of DeFi applications where accounts, transactions, order books, and swaps remain private. Users can protect their trading strategies and positions from public view, preventing front-running and maintaining competitive advantages. Additionally, users can bridge privately into cross-chain DeFi applications, allowing them to participate in DeFi across multiple blockchains while keeping their identity private despite being on an existing transparent blockchain.
This technology makes it possible to bring institutional trading activity on-chain while maintaining the privacy that traditional finance requires. Institutions can privately trade with other institutions globally, without having to touch public markets, enjoying the benefits of blockchain technology such as fast settlement and reduced counterparty risk, without exposing their trading intentions or volumes to the broader market.
Organizations can bring client accounts and assets on-chain while maintaining full compliance. This infrastructure protects on-chain asset trading and settlement strategies, ensuring that sophisticated financial operations remain private. A private world computer also supports private stablecoin issuance and redemption, allowing financial institutions to manage digital currency operations without revealing sensitive business information.
Users have granular control over their privacy settings, allowing them to fine-tune privacy levels for their on-chain identity according to their specific needs. The system enables selective disclosure of on-chain activity, meaning users can choose to reveal certain transactions or holdings to regulators, auditors, or business partners while keeping other information private, meeting compliance requirements.
The shift from transparent blockchains to privacy-preserving infrastructure is the foundation for bringing the next billion users on-chain. Whether you're a developer building the future of private DeFi, an institution exploring compliant on-chain solutions, or simply someone who believes privacy is a fundamental right, now is the time to get involved.
Follow Aztec on X to stay updated on the latest developments in private smart contracts and decentralized privacy technology. Ready to contribute to the network? Run a node and help power the private world computer.
The next Renaissance is here, and it’s being powered by the private world computer.
After eight years of solving impossible problems, the next renaissance is here.
We’re at a major inflection point, with both our tech and our builder community going through growth spurts. The purpose of this rebrand is simple: to draw attention to our full-stack privacy-native network and to elevate the rich community of builders who are creating a thriving ecosystem around it.
For eight years, we’ve been obsessed with solving impossible challenges. We invented new cryptography (Plonk), created an intuitive programming language (Noir), and built the first decentralized network on Ethereum where privacy is native rather than an afterthought.
It wasn't easy. But now, we're finally bringing that powerful network to life. Testnet is live with thousands of active users and projects that were technically impossible before Aztec.
Our community evolution mirrors our technical progress. What started as an intentionally small, highly engaged group of cracked developers is now welcoming waves of developers eager to build applications that mainstream users actually want and need.
A brand is more than aesthetics—it's a mental model that makes Aztec's spirit tangible.
Renaissance means "rebirth"—and that's exactly what happens when developers gain access to privacy-first infrastructure. We're witnessing the emergence of entirely new application categories, business models, and user experiences.
The faces of this renaissance are the builders we serve: the entrepreneurs building privacy-preserving DeFi, the activists building identity systems that protect user privacy, the enterprise architects tokenizing real-world assets, and the game developers creating experiences with hidden information.
This next renaissance isn't just about technology—it's about the ethos behind the build. These aren't just our values. They're the shared DNA of every builder pushing the boundaries of what's possible on Aztec.
Agency: It’s what everyone deserves, and very few truly have: the ability to choose and take action for ourselves. On the Aztec Network, agency is native
Genius: That rare cocktail of existential thirst, extraordinary brilliance, and mind-bending creation. It’s fire that fuels our great leaps forward.
Integrity: It’s the respect and compassion we show each other. Our commitment to attacking the hardest problems first, and the excellence we demand of any solution.
Obsession: That highly concentrated insanity, extreme doggedness, and insatiable devotion that makes us tick. We believe in a different future—and we can make it happen, together.
Just as our technology bridges different eras of cryptographic innovation, our new visual identity draws from multiple periods of human creativity and technological advancement.
Our new wordmark embodies the diversity of our community and the permissionless nature of our network. Each letter was custom-drawn to reflect different pivotal moments in human communication and technological progress.
Together, these letters tell the story of human innovation: each era building on the last, each breakthrough enabling the next renaissance. And now, we're building the infrastructure for the one that's coming.
We evolved our original icon to reflect this new chapter while honoring our foundation. The layered diamond structure tells the story:
The architecture echoes a central plaza—the Roman forum, the Greek agora, the English commons, the American town square—places where people gather, exchange ideas, build relationships, and shape culture. It's a fitting symbol for the infrastructure enabling the next leap in human coordination and creativity.
From the Mughal and Edo periods to the Flemish and Italian Renaissance, our brand imagery draws from different cultures and eras of extraordinary human flourishing—periods when science, commerce, culture and technology converged to create unprecedented leaps forward. These visuals reflect both the universal nature of the Renaissance and the global reach of our network.
But we're not just celebrating the past —we're creating the future: the infrastructure for humanity's next great creative and technological awakening, powered by privacy-native blockchain technology.
Join us to ask questions, learn more and dive into the lore.
Join Our Discord Town Hall. September 4th at 8 AM PT, then every Thursday at 7 AM PT. Come hear directly from our team, ask questions, and connect with other builders who are shaping the future of privacy-first applications.
Take your stance on privacy. Visit the privacy glyph generator to create your custom profile pic and build this new world with us.
Stay Connected. Visit the new website and to stay up-to-date on all things Noir and Aztec, make sure you’re following along on X.
The next renaissance is what you build on Aztec—and we can't wait to see what you'll create.
Aztec’s Public Testnet launched in May 2025.
Since then, we’ve been obsessively working toward our ultimate goal: launching the first fully decentralized privacy-preserving layer-2 (L2) network on Ethereum. This effort has involved a team of over 70 people, including world-renowned cryptographers and builders, with extensive collaboration from the Aztec community.
To make something private is one thing, but to also make it decentralized is another. Privacy is only half of the story. Every component of the Aztec Network will be decentralized from day one because decentralization is the foundation that allows privacy to be enforced by code, not by trust. This includes sequencers, which order and validate transactions, provers, which create privacy-preserving cryptographic proofs, and settlement on Ethereum, which finalizes transactions on the secure Ethereum mainnet to ensure trust and immutability.
Strong progress is being made by the community toward full decentralization. The Aztec Network now includes nearly 1,000 sequencers in its validator set, with 15,000 nodes spread across more than 50 countries on six continents. With this globally distributed network in place, the Aztec Network is ready for users to stress test and challenge its resilience.
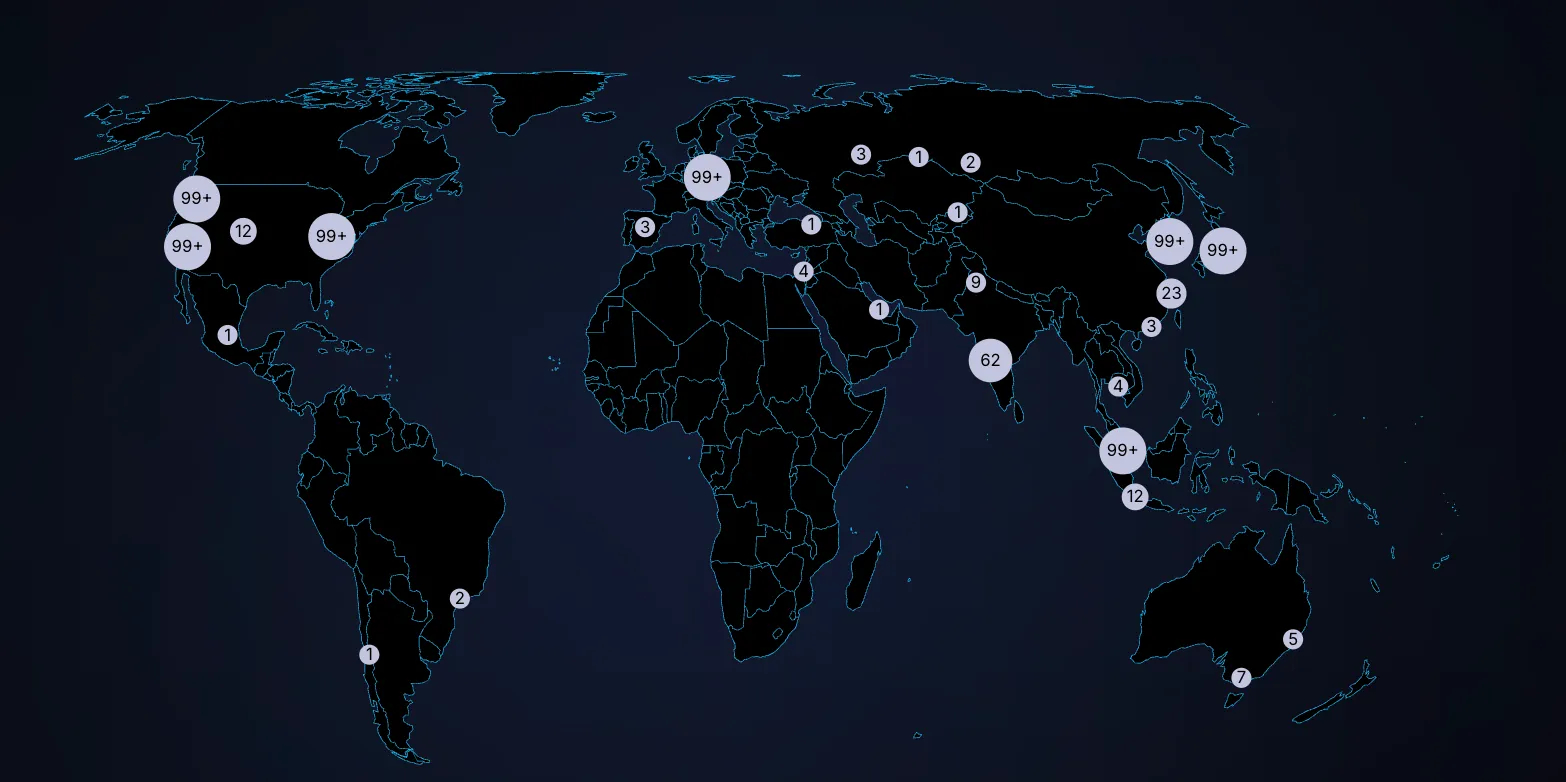
We're now entering a new phase: the Adversarial Testnet. This stage will test the resilience of the Aztec Testnet and its decentralization mechanisms.
The Adversarial Testnet introduces two key features: slashing, which penalizes validators for malicious or negligent behavior in Proof-of-Stake (PoS) networks, and a fully decentralized governance mechanism for protocol upgrades.
This phase will also simulate network attacks to test its ability to recover independently, ensuring it could continue to operate even if the core team and servers disappeared (see more on Vitalik’s “walkaway test” here). It also opens the validator set to more people using ZKPassport, a private identity verification app, to verify their identity online.
The Aztec Network testnet is decentralized, run by a permissionless network of sequencers.
The slashing upgrade tests one of the most fundamental mechanisms for removing inactive or malicious sequencers from the validator set, an essential step toward strengthening decentralization.
Similar to Ethereum, on the Aztec Network, any inactive or malicious sequencers will be slashed and removed from the validator set. Sequencers will be able to slash any validator that makes no attestations for an entire epoch or proposes an invalid block.
Three slashes will result in being removed from the validator set. Sequencers may rejoin the validator set at any time after getting slashed; they just need to rejoin the queue.
In addition to testing network resilience when validators go offline and evaluating the slashing mechanisms, the Adversarial Testnet will also assess the robustness of the network’s decentralized governance during protocol upgrades.
Adversarial Testnet introduces changes to Aztec Network’s governance system.
Sequencers now have an even more central role, as they are the sole actors permitted to deposit assets into the Governance contract.
After the upgrade is defined and the proposed contracts are deployed, sequencers will vote on and implement the upgrade independently, without any involvement from Aztec Labs and/or the Aztec Foundation.
Starting today, you can join the Adversarial Testnet to help battle-test Aztec’s decentralization and security. Anyone can compete in six categories for a chance to win exclusive Aztec swag, be featured on the Aztec X account, and earn a DappNode. The six challenge categories include:
Performance will be tracked using Dashtec, a community-built dashboard that pulls data from publicly available sources. Dashtec displays a weighted score of your validator performance, which may be used to evaluate challenges and award prizes.
The dashboard offers detailed insights into sequencer performance through a stunning UI, allowing users to see exactly who is in the current validator set and providing a block-by-block view of every action taken by sequencers.
To join the validator set and start tracking your performance, click here. Join us on Thursday, July 31, 2025, at 4 pm CET on Discord for a Town Hall to hear more about the challenges and prizes. Who knows, we might even drop some alpha.
To stay up-to-date on all things Noir and Aztec, make sure you’re following along on X.
On May 1st, 2025, Aztec Public Testnet went live.
Within the first 24 hours, over 20k users visited the Aztec Playground and started to send transactions on testnet. Additionally, 10 apps launched live on the testnet, including wallets, block explorers, and private DeFi and NFT marketplaces. Launching a decentralized testnet poses significant challenges, and we’re proud that the network has continued to run despite high levels of congestion that led to slow block production for a period of time.
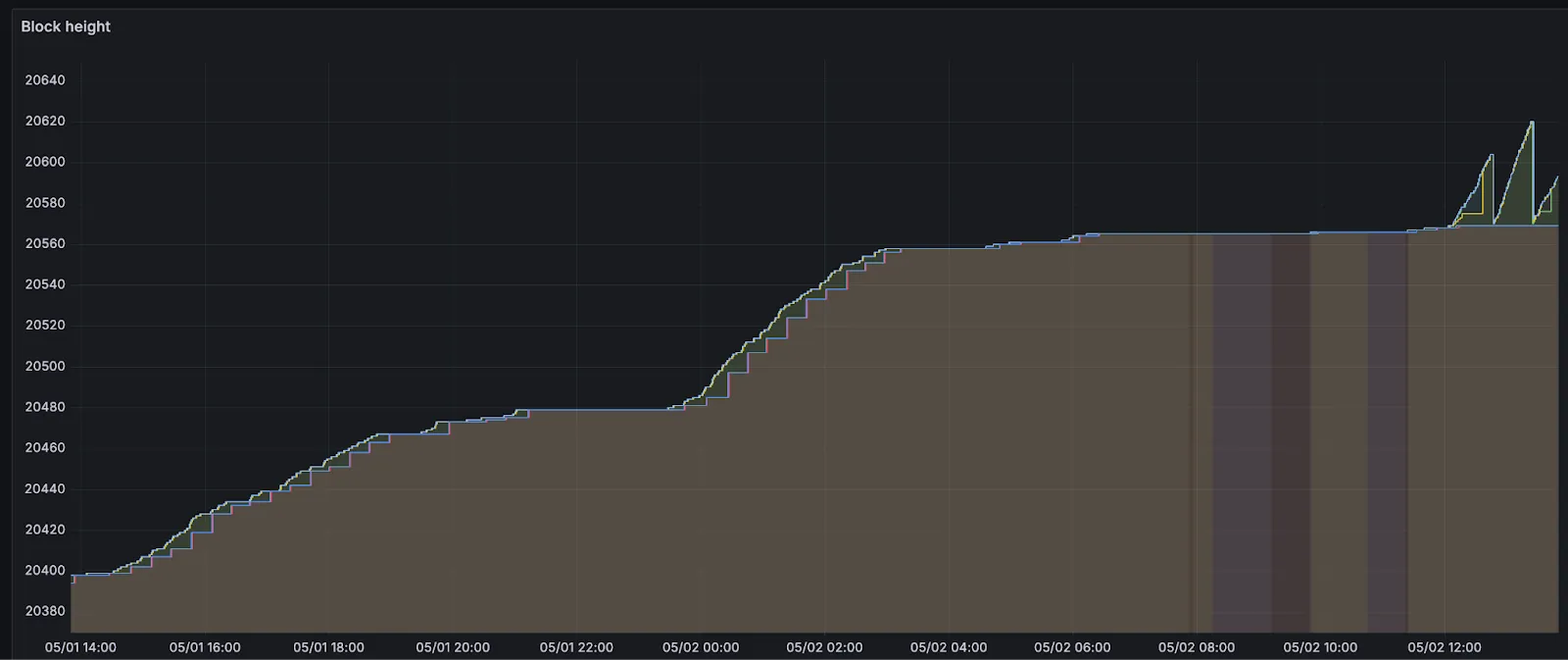
Around 6 hours after announcing the network launch, more than 150 sequencers had joined the validator set to sequence transactions and propose blocks for the network. 500+ additional full nodes were spun up by node operators participating in our Discord community. These sequencers were flooded with over 5k transactions before block production slowed. Let’s dive into why block production slowed down.
On Aztec, an epoch is a group of 32 blocks that are rolled up for settlement on Ethereum. Leading up to the slowdown of block production, there were entire epochs with full blocks (8 transactions, or 0.2TPS) in every slot. The sequencers were building blocks and absorbing the demand for blockspace from users of the Aztec playground, and there was a build up of 100s of pending transactions in sequencer mempools.
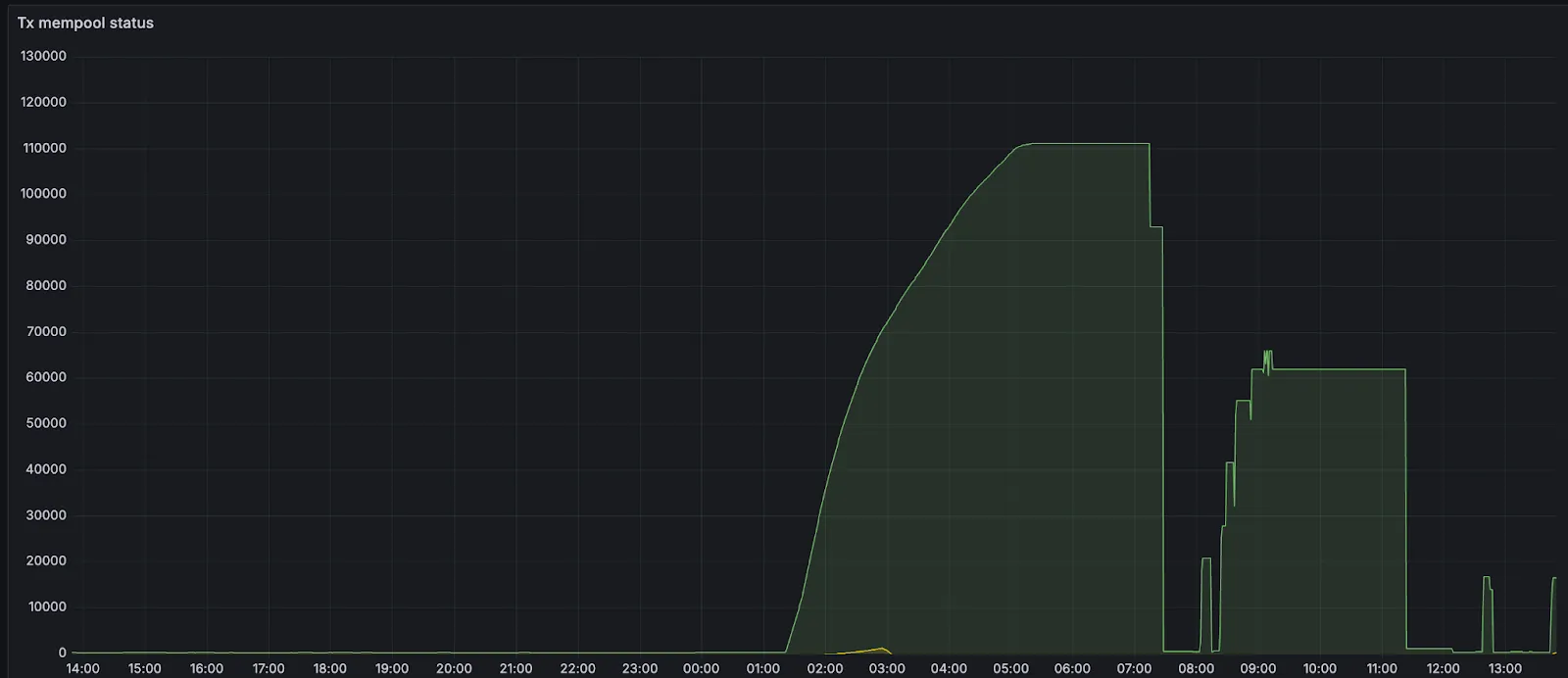
Issues arose when these transactions started to exceed the mempool size, which was configured to hold only 100mb or about 700 transactions.
As many new validators were brought through the funnel and started to come online, the mempools of existing validators (already full at 700 transactions) and new ones (at 0 transactions) diverged significantly. When earlier validators proposed blocks, newer validators didn't have the transactions and could not attest to blocks because the request/response protocol wasn't aggressive enough. When newer validators made proposals, earlier validators didn't have transactions (their mempools were full), so they could not attest to blocks.
New validators then started to build up pending transactions. When validators with full mempools requested missing transactions from peers, they would evict existing transactions from their mempools (mempool is at max memory) based on priority fee. All transactions had default fee settings, so validators were randomly ejecting transactions and were not doing so in lockstep (different validators ejected different transactions). For a little over an hour, the mempools diverged significantly from each other, and block production slowed down to about 20% of the expected rate.
In order to stop the mempool from ejecting transactions, the p2p mempool size was increased. By increasing the mempool size, the likelihood of needing to evict transactions that might soon appear in proposals is reduced. This increases the chances that sequencers already have the necessary transactions locally when they receive a block proposal. As a result, more validators are able to attest to proposals, allowing blocks to be finalized more reliably. Once blocks are included on L1, their transactions are evicted from the mempool. So over time, as more blocks are finalized and transactions are mined, the mempool naturally shrinks and the network will recover on its own.
If you are interested in running a sequencer node visit the sequencer page. Stay up-to-date on Noir and Aztec by following Noir and Aztec on X.
The global political discourse around protecting underage internet users is heating up as lawmakers struggle to achieve safe and secure internet access for minors without imposing on civil liberties.
The European Parliament’s global estimates reveal that one in three children is an internet user, and one in three internet users is under 18. As digital consumption by minors grows, policymakers worldwide are pushing for more stringent age verification laws. However, these efforts are increasingly met with legal and constitutional challenges.
This report explores the potential behind zero-knowledge proof (“ZKP”) identities (“ZKIs”) as an innovative solution for online age verification, offering the dual advantage of enabling robust identity verification while safeguarding personal information.
Click here to read the full report.
On May 1st, 2025, Aztec Public Testnet went live.
Within the first 24 hours, over 20k users visited the Aztec Playground and started to send transactions on testnet. Additionally, 10 apps launched live on the testnet, including wallets, block explorers, and private DeFi and NFT marketplaces. Launching a decentralized testnet poses significant challenges, and we’re proud that the network has continued to run despite high levels of congestion that led to slow block production for a period of time.
Around 6 hours after announcing the network launch, more than 150 sequencers had joined the validator set to sequence transactions and propose blocks for the network. 500+ additional full nodes were spun up by node operators participating in our Discord community. These sequencers were flooded with over 5k transactions before block production slowed. Let’s dive into why block production slowed down.
On Aztec, an epoch is a group of 32 blocks that are rolled up for settlement on Ethereum. Leading up to the slowdown of block production, there were entire epochs with full blocks (8 transactions, or 0.2TPS) in every slot. The sequencers were building blocks and absorbing the demand for blockspace from users of the Aztec playground, and there was a build up of 100s of pending transactions in sequencer mempools.
Issues arose when these transactions started to exceed the mempool size, which was configured to hold only 100mb or about 700 transactions.
As many new validators were brought through the funnel and started to come online, the mempools of existing validators (already full at 700 transactions) and new ones (at 0 transactions) diverged significantly. When earlier validators proposed blocks, newer validators didn't have the transactions and could not attest to blocks because the request/response protocol wasn't aggressive enough. When newer validators made proposals, earlier validators didn't have transactions (their mempools were full), so they could not attest to blocks.
New validators then started to build up pending transactions. When validators with full mempools requested missing transactions from peers, they would evict existing transactions from their mempools (mempool is at max memory) based on priority fee. All transactions had default fee settings, so validators were randomly ejecting transactions and were not doing so in lockstep (different validators ejected different transactions). For a little over an hour, the mempools diverged significantly from each other, and block production slowed down to about 20% of the expected rate.
In order to stop the mempool from ejecting transactions, the p2p mempool size was increased. By increasing the mempool size, the likelihood of needing to evict transactions that might soon appear in proposals is reduced. This increases the chances that sequencers already have the necessary transactions locally when they receive a block proposal. As a result, more validators are able to attest to proposals, allowing blocks to be finalized more reliably. Once blocks are included on L1, their transactions are evicted from the mempool. So over time, as more blocks are finalized and transactions are mined, the mempool naturally shrinks and the network will recover on its own.
If you are interested in running a sequencer node visit the sequencer page. Stay up-to-date on Noir and Aztec by following Noir and Aztec on X.
When Aztec first got started, the world of zero-knowledge proving systems and applications was in its infancy. There was no PLONK, no Noir, no programmable privacy, and it wasn’t clear that demand for onchain privacy was even strong enough to necessitate a new blockchain network.
After a decade of building, revolutionary breakthroughs in privacy technology have paved the way to, and now set the stage for, mainnet including: PLONK, a novel proving system for user-level privacy and programmability that yielded zk.money and Aztec Connect, which was a pivotal moment for privacy and encryption solutions; Noir, an intuitive zero-knowledge, Rust-like programming language; and a client-side library for a private execution environment (PXE). These tools allow developers to explore privacy-preserving applications across any use case where protecting sensitive data is a critical function.
In 2023 and 2024 Aztec was named by Electric Capital as one of the fastest-growing developer ecosystems. The next generation of applications on Ethereum are already being built using parts of the Aztec stack, like Noir. Projects such as zkPassport and zkEmail are unlocking key identity use cases, while other applications like Anoncast (built in one weekend) have caught the attention of heavyweights like Vitalik Buterin and Laura Shin.
Earlier this month, we announced the successful testing of the first decentralized upgrade process for an L2, with over 100 sequencers participating. Now, with the mission to bring programmable privacy to the masses, the Aztec Public Testnet is here and, for the first time ever, open to developers to build fully private applications on Ethereum.

The Aztec Network will launch fully decentralized from day one.
Not because it’s a flex, but because true privacy can only be achieved when there is no central entity that has potential backdoor access.
Imagine logging into your hot wallet using web2 auth with Google or iCloud, or proving you’re a U.S. citizen onchain without revealing your passport information. For this, you need onchain privacy, and true privacy needs full decentralization so the user can maintain control over their data.
This is the vision for the Aztec Network.
Like Zac, our CEO and Co-founder, said in his talk Privacy: The Missing Link, “there are three fundamental attributes required to bridge the gap and bring the world onchain: interfacing with web2 systems, linking accounts to identities, and establishing digital sovereignty.”
Launching a decentralized network is a complex task filled with lots of intricacies and nuances to navigate. The Aztec Public Testnet plays a crucial role in stress-testing the network, identifying early issues, and ensuring its participants work as intended – ultimately leading to a more robust mainnet.
There are two ways you can participate in the network: as a developer who wants to build and deploy applications (with end-to-end privacy) or as a node operator powering the network.
Aztec enables developers to build with both private and public state.
Smart contracts on Aztec blend private functions that execute on the client side with public functions that are executed by sequencers on the Aztec Network. This allows you to customize your contract with both public and private components while deploying them to a fully decentralized network.
The fastest way to get started with the Aztec Public Testnet is to deploy a smart contract using the Playground. If you’re a developer, visit our dev landing page to connect to Testnet and deploy on the Aztec Network.
The Aztec Network is run by a decentralized sequencer and prover network.
Sequencers propose and produce blocks using consumer hardware and are responsible for proposing and voting on network upgrades. Provers participate in a decentralized prover network and are selected to prove the rollup integrity.
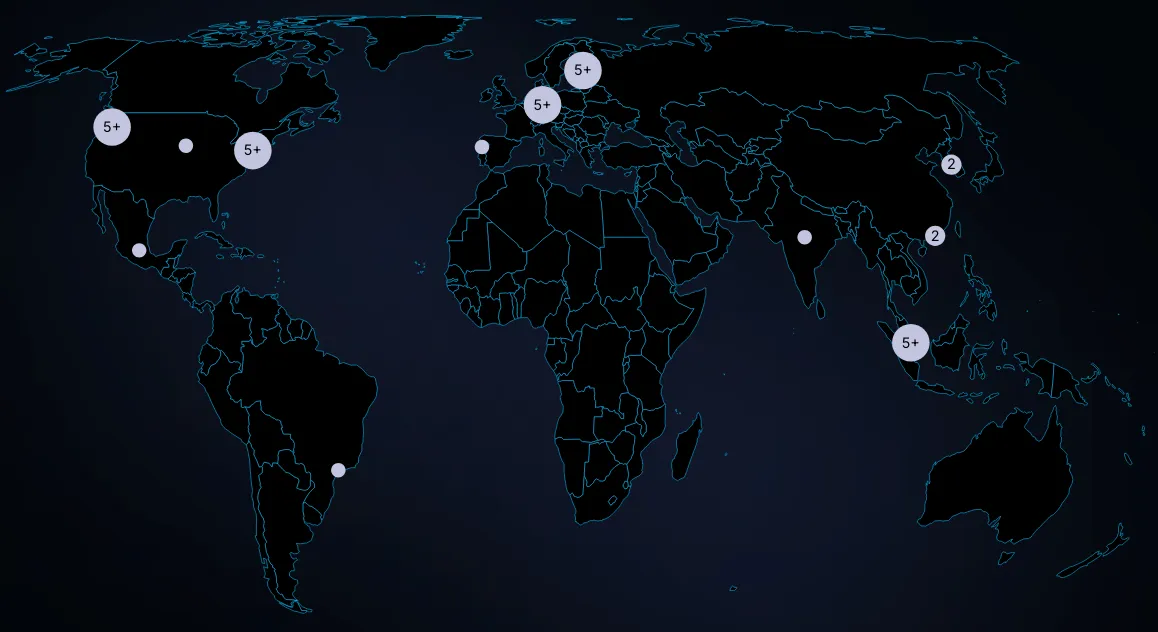
No airdrops. No marketing gimmicks. We just want to create a community of highly skilled operators who share the vision of a fully decentralized privacy-preserving network. Anyone can boot up a sequencer node and access the testnet faucet. See the sequencer quickstart to get started. Apply to get a special Discord role and peer support from experienced node operators leading the Aztec Network.
To see existing applications and get inspo for what you want to build on the Aztec Public Testnet, check out our Ecosystem page. If you’ve already built an app and would like to be featured, submit your app here.

Next, head to the Playground to try out the Aztec Public Testnet, where you can deploy and interact with privacy-preserving smart contracts. Tools and infrastructure to start building wallets, bridges, and explorers are already available.
If you’re a developer, click ➡️ here to get started and deploy your smart contract in literal minutes.
If you’re a node operator, click ➡️ here to set up and run a node.
Stay up-to-date on Noir and Aztec by following Noir and Aztec on X.
Aztec will be a fully decentralized, permissionless and privacy-preserving L2 on Ethereum. The purpose of Aztec’s Public Testnet is to test all the decentralization mechanisms needed to launch a strong and decentralized mainnet. In this post, we’ll explore what full decentralization means, how the Aztec Foundation is testing each aspect in the Public Testnet, and the challenges and limitations of testing a decentralized network in a testnet environment.
Three requirements must be met to achieve decentralization for any zero-knowledge L2 network:
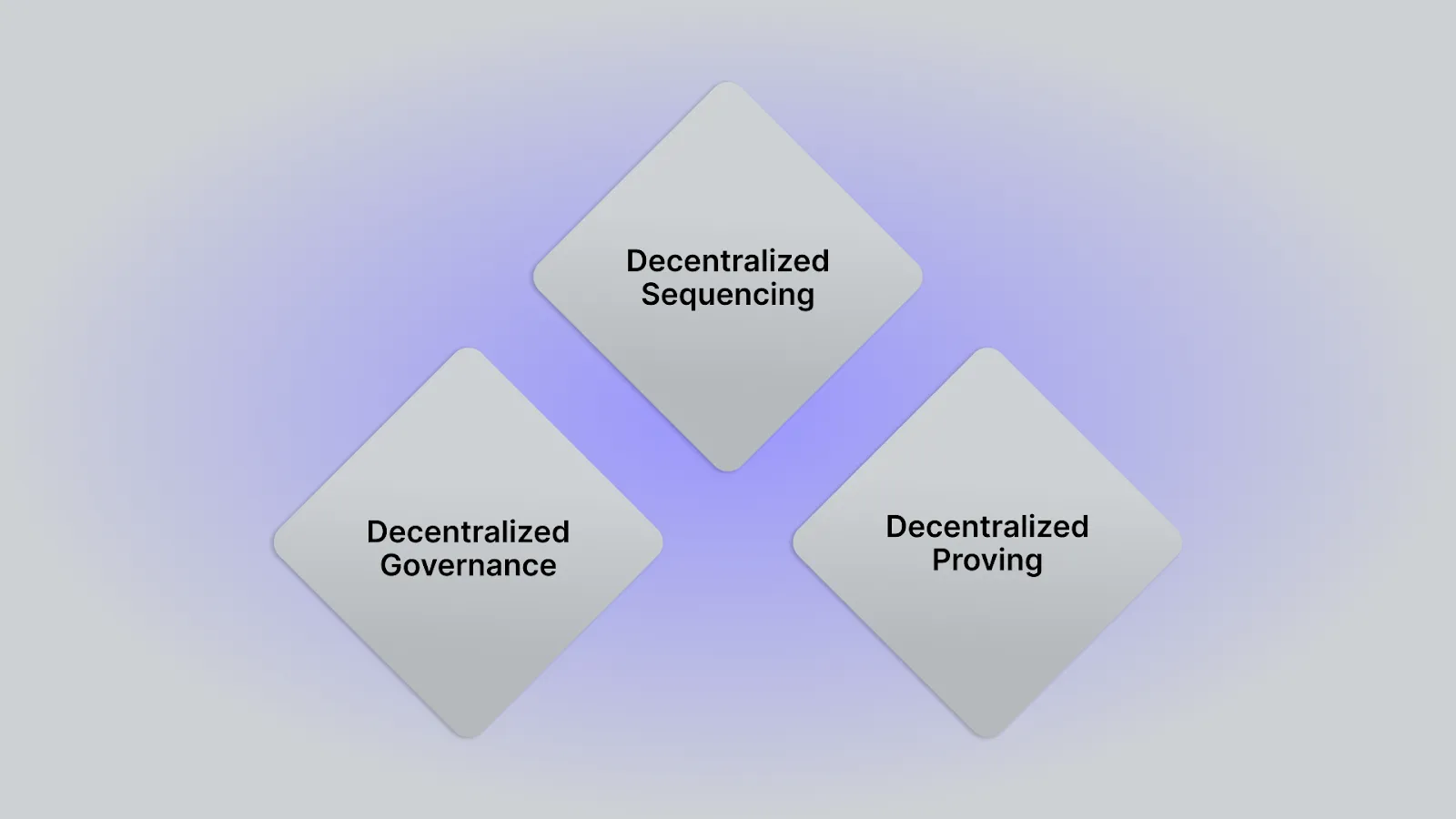
Decentralization across sequencing, proving, and governance is essential to ensure that no single party can control or censor the network. Decentralized sequencing guarantees open participation in block production, while decentralized proving ensures that block validation remains trustless and resilient, and finally, decentralized governance empowers the community to guide network evolution without centralized control.
Together, these pillars secure the rollup’s autonomy and long-term trustworthiness. Let’s explore how Aztec’s Public Testnet is testing the implementation of each of these aspects.
Aztec will launch with a fully decentralized sequencer network.
This means that anyone can run a sequencer node and start sequencing transactions, proposing blocks to L1 and validating blocks built by other sequencers. The sequencer network is a proof-of-stake (PoS) network like Ethereum, but differs in an important way. Rather than broadcasting blocks to every sequencer, Aztec blocks are validated by a randomly chosen set of 48 sequencers. In order for a block to be added to the L2 chain, two-thirds of the sequencers need to verify the block. This offers users fast preconfirmations, meaning the Aztec Network can sequence transactions faster while utilizing Ethereum for final settlement security.
PoS is fundamentally an anti-sybil mechanism—it works by giving economic weight to participation and slashing malicious actors. At the time of Aztec’s mainnet, this will allow sequencers to vote out bad actors and burn their staked assets. On the Public Testnet, where there are no real economic incentives, PoS doesn't function properly. To address this, we introduced a queue system that limits how quickly new sequencers can join, helping to maintain network health and giving the network time to react to potential malicious behavior.
Behind the scenes, a contract handles sequencer onboarding—it mints staking assets, adds sequencers to the set, and can remove them if necessary. This contract is just for Public Testnet and will be removed on Mainnet, allowing us to simulate and test the decentralized sequencing mechanisms safely.
Aztec will also launch with a fully decentralized prover network.
Provers generate cryptographic proofs that verify the correctness of public transactions, culminating in a single rollup proof submitted to Ethereum. Decentralized proving reduces centralization risk and liveness failures, but also opens up a marketplace to incentivize fast and efficient proof generation. The proving client developed by Aztec Labs involves three components:
Once the final proof has been computed, the proving node sends the proof to L1 for verification. The Aztec Network splits proving rewards amongst everyone who submits a proof on time, reducing centralization risk where one entity with large compute dominates the network.
For Aztec’s Public Testnet, anyone can spin up a prover node and start generating proofs. Running a prover node is more hardware-intensive than running a sequencer node, requiring ~40 machines with an estimated 16 cores and 128GB RAM each. Because running provers can be cost-intensive and incur the same costs on a testnet as it will on mainnet, Aztec’s Public Testnet will throttle transactions to 0.2 per second (TPS).
Keeping transaction volumes low allows us to test a fully decentralized prover network without overwhelming participating provers with high costs before real network incentives are in place.
Finally, Aztec will launch with fully decentralized governance.
In order for network upgrades to occur, anyone can put forward a proposal for sequencers to consider. If a majority of sequencers signal their support, the proposal gets sent to a vote. Once it passes the vote, anyone can execute the script that will implement the upgrade. Note: For this testnet, the second phase of voting will be skipped.
Decentralized governance is an important step in enabling anyone to participate in shaping the future of the network. The goal of the public testnet is to ensure the mechanisms are functioning properly for sequencers to permissionlessly join and control the Aztec Network from day 1.
One additional aspect to consider with regard to full decentralization is the role of network users in decentralizing the compute load of the network.
Aztec Labs has developed groundbreaking technology to make end-to-end programmable privacy possible. First with the release of Plonk, and later refinements like MegaHonk, which make it feasible to generate client-side ZKPs. Client-side proofs keep sensitive data on the user’s device while still enabling users to interact with and store this information privately onchain. They also help to scale throughput by pushing execution to users. This decentralizes the compute requirements and means users can execute arbitrary logic in their private functions.
Sequencers and provers on the Aztec Network are never able to see any information that users or applications want to keep private, including accounts, activity, balances, function execution, or other data of any kind.
Aztec’s Public Testnet is shipping with a full execution environment, including the ability to create client-side proofs in the browser. Here are some time estimations to expect for generating private, client-side proofs:
Aztec’s Public Testnet is designed to rigorously test decentralization across sequencing, proving, and governance ahead of our mainnet launch. The network design ensures no single entity can control or censor activity, empowering anyone to participate in sequencing transactions, generating proofs, and proposing governance changes.
Visit the Aztec Testnet page to start building with programmable privacy and join our community on Discord.