TL;DR
The proof generation for a privacy-preserving zk-rollup differs a lot from that of a general-purpose zk-rollup. The reason for this is that there is specific data in a given transaction (processed by private functions) that we want to stay completely private. In this article, we explore the client-side proof generation used for proving private functions’ correct execution and explain how it differs from proof generation in general-purpose rollups.

Contents
- What proofs are and how they work in general-purpose zk-rollups
- How proofs work in Aztec
- Proving functions’ correct execution
- For public functions: rollup-side proof generation
- For private functions: client-side proof generation
- An example proof
- How client-side proof generation decreases memory requirements
- Appendix: other details of client-side proof generation.
- Summary
What proofs are and how they work in general-purpose zk-rollups
Disclaimer: If you’re closely familiar with how zk-rollups work, feel free to skip this section.
Before we dive into proofs on Aztec, specifically the privacy-first nature of Aztec’s zk-rollup, let’s recap how proofs work on general-purpose zk-rollups.
When a stateful blockchain executes transactions, it conducts a state transition. If the state of the network was originally A, then a set of transactions (a block) is executed on the network, the state of the network is now B.
Rollups are stateful blockchains as well. They use proofs to ensure that the state transition was executed correctly. The proof is generated and verified for every block. All proofs are posted on L1, and anyone can re-verify them to ensure that the state transition was done correctly.
For a general-purpose zk-rollup, proof generation is very straightforward, as all data is public. Both the sequencer and the prover see all the transaction data, public states are public, and the data necessary to reconstruct each state transition is posted on L1.
How proofs work in Aztec
Aztec’s zk-rollups are a different story. As we mentioned in the previous article, in the Aztec network, there are two types of state: public and private.

Aztec smart contracts (written in Noir) are composed of two types of functions: private and public.
- Private functions – user-owned state, client-side proof generation
- Public functions – global/public state, rollup-side proof generation
For both of these, we need proof of correct execution. However, as the anatomy of private and public functions is pretty different, their proof generation is pretty different too.
As a brief overview of how Aztec smart contracts are executed: first, all private functions are executed and then all public functions are executed.
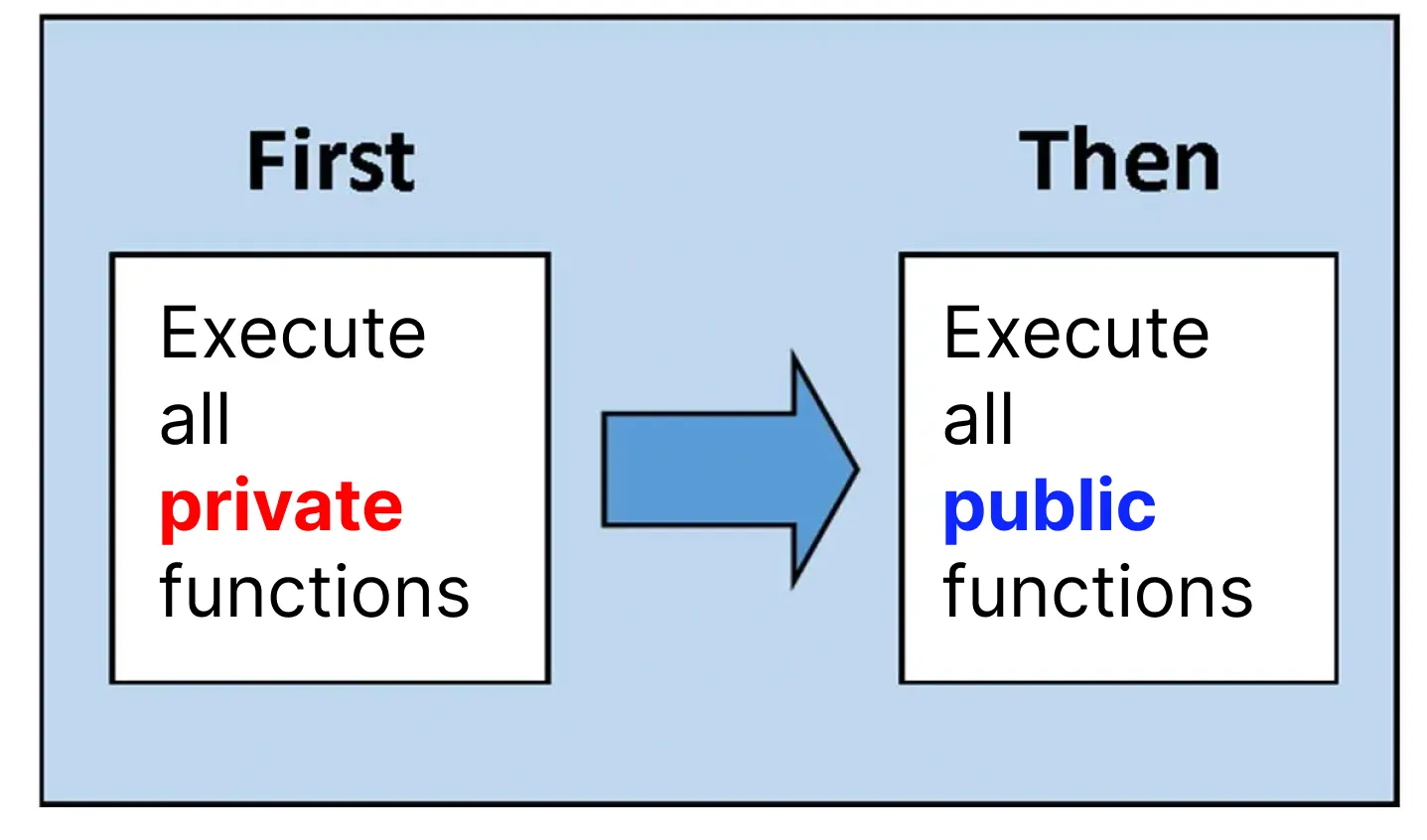
However, diving into the anatomy of Aztec smart contracts is outside the scope of this piece. To learn more about it, check the previous article.
Here, we will focus on the correct proof generation execution of private functions and why it is a crucial element of a privacy-first zk-rollup.
The concepts of private state and private functions in blockchain might seem a little unusual. The following map describes the path of this article, where we will shed some light on the difference between how proofs work for private and public states respectively.
Proving functions’ correct execution
For public functions: rollup-side proof generation
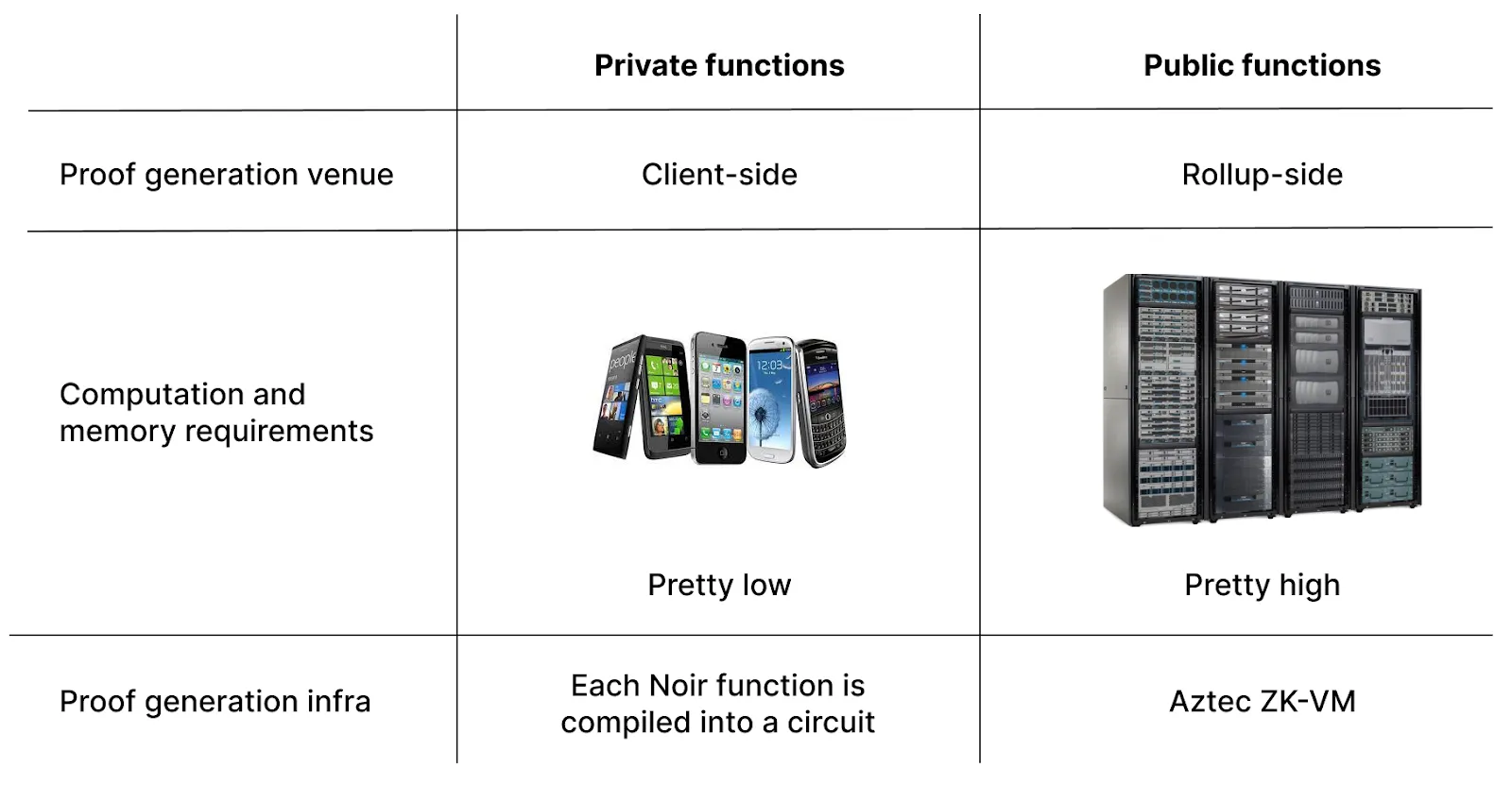
Let’s start by looking at public function execution, as it is more similar to other general-purpose zk-rollups.
Public state is the global state available to everyone. The sequencer executes public functions, while the prover generates the correct execution proof. In particular, the last step means that the function (written in Noir) is compiled in a specific type of program representation, which is then evaluated by a virtual machine (VM) circuit. Evaluated means that it will execute the set of instructions one by one, resulting in either a proof of correct execution or failure. The rollup-side prover can handle heavy computation as it is run on powerful hardware (i.e. not a smartphone or a computer browser as in the client-side case).
For private functions: client-side proof generation
Private state on the other hand is owned by users. When generating proof of a private transaction's correct execution, we want all data to stay private. It means we can’t have a third-party prover (as in the case of public state) because data would be subsequently exposed to the prover and thus no longer be private.
In the case of a private transaction, the transaction owner (the only one who is aware of the transaction data) should generate the proof on their own. That is, the proof of a private transaction's correct execution has to be generated client-side.
That means that every Aztec network user should be able to generate a proof on their smartphone or laptop browser. Furthermore, as an Aztec smart contract might be composed of a number of private functions, every Aztec network user should be able to generate a number of proofs (one proof for each private function).
On the rollup side, block proofs are generated using ZK-VM (ZK virtual machine). On the private side, there is no VM.

Instead, each private function is compiled into a static circuit on its own.
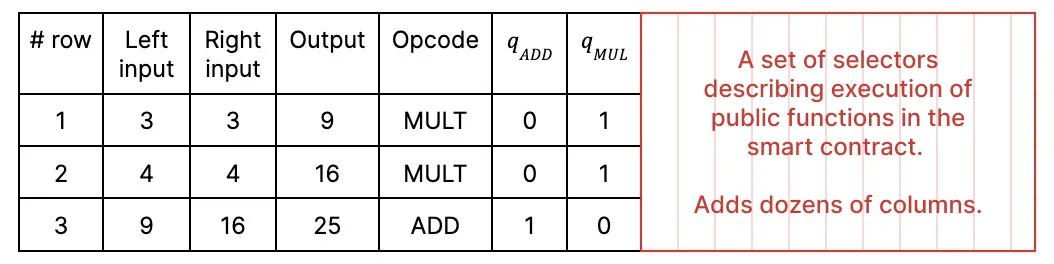
When we say “a circuit”, we’re referring to a table with some precomputed values filled in. This table describes the sequence of instructions (like MUL and ADD) to be executed during a particular run of the code.
There are a bunch of predefined relations between the rows and columns of the table, for example, copy constraints that state that the values of a number of wires are expected to be the same.
Let’s take a look at a quick example:

In the diagram above, we have two gates, Gate 1 (+) and Gate 2 (x). As we can see, z is both the output of Gate 1 (denoted as w3, wire 3) and the left input to Gate 2 (denoted as w4, wire 4). So, we need to ensure that the value of the output of Gate 1 is the same as the value of the left input of Gate 2. That is, that w3 = w4. That’s exactly what we call “checking copy constraints”.
When we say that the verifier verifies the circuit, we mean it checks that these predefined relations hold for all rows and columns.
An example proof
Disclaimer: the following example reflects the general logic in a simplified way. The real functions are much more complex.
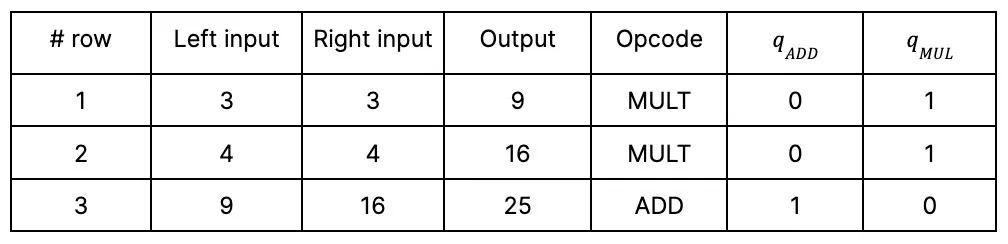
Assume we have a function a2+b2=c2. The goal is to prove that equality holds for specific inputs and outputs. Assume a = 3, b = 4, c = 5.
As a piece of code, we can represent the function as the following:

When the function is executed, the result of each step is written down in a table. When this table is filled with the results of the specific function execution on specific values, it’s called an execution trace.

This is just a fragment of the table, with values and opcode names. However, to instruct the computer about which operation should be executed in which specific row, the opcode name is not enough; we need selectors.
Selectors are gates that refer to toggling operations (like an on/off switch). In our example, we will use a simplified Plonk equation with two selectors: qADD for the addition gate and qMUL for the multiplication gate. The simplified Plonk equation is: qMUL(a*b)+qADD(a+b)-c=0.
Turning them on and off, that is, assigning values 1 and 0, the equation will transform into different operations. For example, to perform the addition of a and b, we put qADD= 1, qMUL=0, so the equation is a+b-c =0.
So, for each performed operation, we also store in the table its selectors:
How client-side proof generation decrease memory requirements
In the case of private functions, as each function is compiled into a static circuit, all the required selectors are put into the table in advance. In particular, when the smart contract function is compiled, it outputs a verification key containing a set of selectors.
In the case of a smart contract, the circuit is orders of magnitude larger as it contains more columns with selectors for public function execution. Furthermore, there are more relation checks to be done. For example, one needs to check that the smart contract bytecode really does what it is expected to do (that is, that the turned selectors are turned according to the provided bytecode commitment).
As a mental model, you can think about a smart contract circuit as a table where 50 out of 70 columns are reserved for the selectors' lookup table. Storing the entire table requires a lot of memory.
Now you see the difference between circuit size for client-side and rollup-side proof generation: on the client-side, circuits are much smaller with lower memory and compute requirements. This is one of the key reasons why the proofs of private functions' correct execution can be generated on users’ devices.
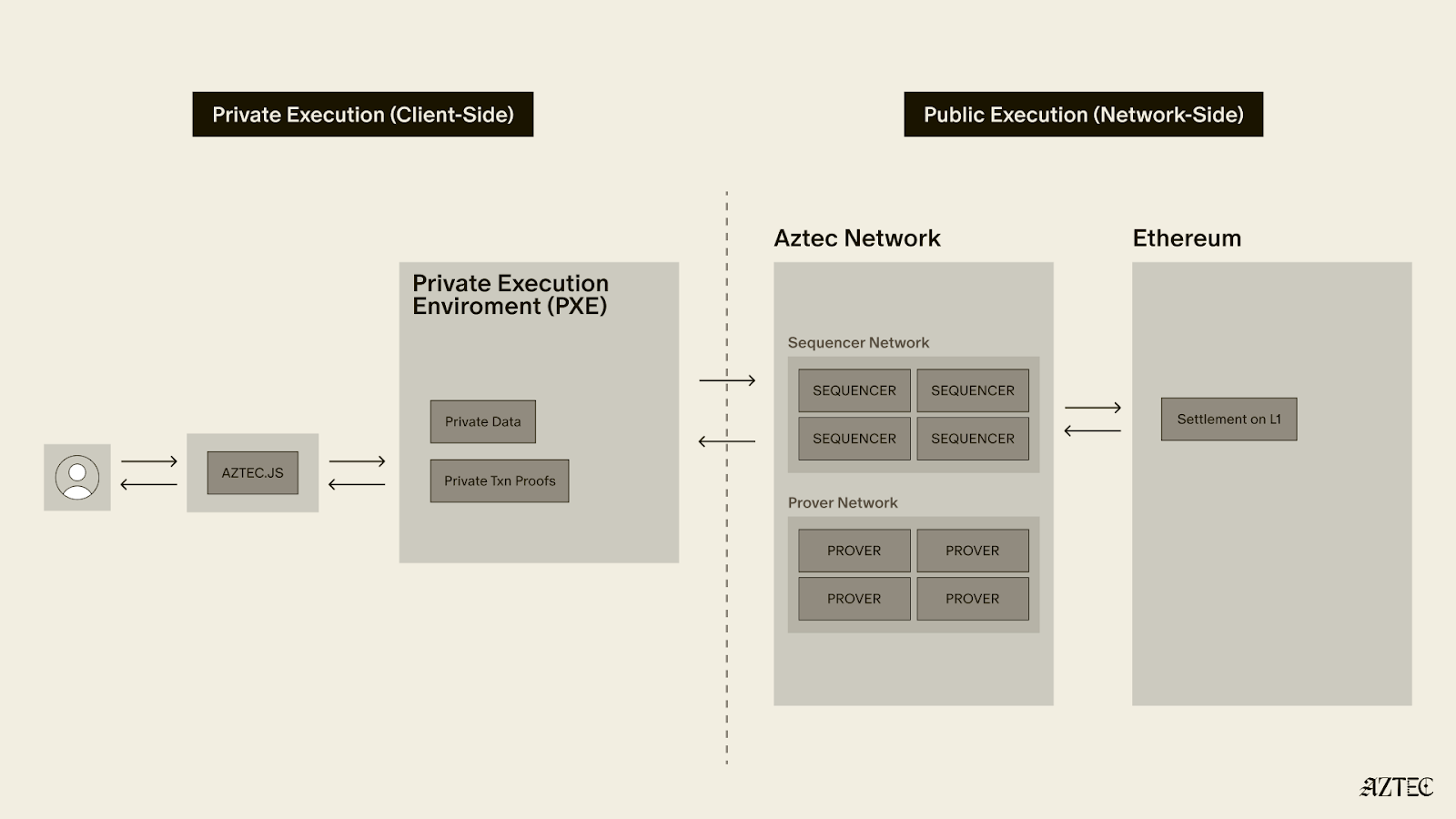
Appendix: other details of client-side proof generation
- To further decrease memory and computation requirements for the prover, we use a specific proving system, Honk, which is a highly optimized Plonk developed by Aztec Labs. Honk is a combination of Plonk-ish arithmetization, the sum-check protocol (which has some nice memory tricks), and a multilinear polynomial commitment scheme.
- Some gadgets that may be added to Honk to make it even more efficiet include Goblin Plonk, a specific type of recursion developed by Aztec Labs, and ProtoGalaxy, developed by Liam Eagen and Ariel Gabizon.
- Goblin Plonk allows a resource-constrained prover to construct a zk-snark with multiple layers of recursion. That perfectly fits the case of client-side proof generation, where a proof of each private function in a smart contract is an additional layer of the recursion. The trick is that expensive operations (such as Elliptic Curve operations) at each recursion layer are postponed to the last step instead of being executed at each. The recursion ends in one single proof for all the private functions in a smart contract.
- This proof is then verified by the rollup circuit. The recursive verification of this proof is pretty resource intensive. However, as it is performed rollup-side, it has enough computation and memory resources.
- ProtoGalaxy is a folding scheme that optimizes the recursive verifier work. It allows for folding multiple instances in one step, decreasing the verifier’s work in each folding step to a constant.
- Diving into Honk and its optimizations is outside the scope of this article, but we promise to cover it soon in upcoming pieces.
Summary
Client-side proof generation is a pretty novel approach for the blockchain domain. However, for privacy-preserving solutions, it is an absolute must-have. Aztec Labs has spent years developing the protocol and cryptography architecture that make client-side proof generation performance feasible for the production stage.
You can help build it further.
- Build with the Aztec Sandbox: A local developer testnet of Aztec’s privacy-first L2 on Ethereum
- Build with Noir: A privacy programming language developed by Aztec Labs
- Join the Aztec Labs team – we’re hiring on our cryptography, growth, and operations teams



.png)